
Abstract
Task scheduling and resource management are critical for improving system performance and enhancing consumer satisfaction in distributed computing environments. The dynamic nature of tasks and the environments creates new challenges for schedulers. To solve this problem, researchers developed fuzzy-based scheduling algorithms. Fuzzy logic is ideal for decision-making processes since it has a low computational complexity and processing power requirement. Motivated by the extensive research efforts in the distributed computing and fuzzy applications, we present a review of high-quality articles related to fuzzy-based scheduling algorithms in grid, cloud, and fog published between 2005 and June 2023. This paper discusses and compares fuzzy-based scheduling schemes based on merits and demerits, evaluation techniques, simulation environments, and important parameters. We begin by introducing distributed environments, and scheduling process followed by their surveys. This study has summarized several domains where fuzzy logic is used in distributed systems. More specifically, the basic concepts of fuzzy inference system and motivations of fuzzy theory in scheduler are addressed smoothly. A fuzzy-based scheduling algorithm employs fuzzy logic in different ways (e.g., calculating fitness functions, assigning tasks to fog/cloud nodes, and clustering tasks or resources). Finally, open challenges and promising future directions in fuzzy-based scheduling are identified and discussed.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Task scheduling is becoming increasingly important as more clients use distributed systems. It is critical to consider a number of critical factors when managing Information Technology (IT) systems, including availability, execution time, and reliability. As a result, it is difficult to construct a model that integrates all of these performance metrics due to factors that are unrelated (Chiang et al. 2023; Mangalampalli et al. 2023a). To develop effective scheduling algorithms, it is vital to understand the limitations and problems associated with various algorithms. In this paper, fuzzy-based task scheduling strategies and associated metrics are discussed in grid, cloud, and fog environments. The main contributions of this study are as follows:
-
Analyzing fuzzy logic applications in distributed systems and the advantages and disadvantages of fuzzy logic.
-
Presenting a comprehensive analysis of the fuzzy-based scheduling in grid, cloud, and fog computing.
-
Developing a taxonomy to categorize grid, cloud, and fog scheduling algorithms.
-
Comparing the existing fuzzy-based scheduling algorithms according to QoS criteria and their appropriate applications.
-
Investigating the details of fuzzy systems that are used in schedulers.
-
Analyzing the evaluation tools used to evaluate the different approaches.
-
Proposing the possible future research challenges and opening issues.
1.1 Related surveys
It is critical that cloud computing users select the best resources for their tasks, which requires examining a variety of factors that affect their performance. In distributed systems, NP-complete problems are crucial for task scheduling algorithms. Recently, several surveys have been published in the literature due to the importance of task scheduling in research. In 2014, Chopra and Singh (2014) classified hybrid cloud scheduling techniques based on their features and functions. Wadhonkar and Theng (2016) compared several cloud-based task scheduling algorithms. Meriam and Tabbane (2017) identified different job scheduling algorithms and their applications. Hazra et al. (2018a) assessed a range of scheduling algorithms that aim to reduce energy consumption in cloud infrastructure as part of a study conducted in 2018. In 2018, Naha et al. (2018) presented an overview of fog computing scheduling algorithms. This comparison compared algorithms that used available resources more efficiently.
Hazra et al. (2018b) compared cost parameters to task scheduling algorithms in 2018. In 2020, Alizadeh et al. (2020) provided an overview of cloud-fog task scheduling based on methods, tools, and restrictions. Ghafari et al. (2022) provided an in-depth review of scheduling algorithms. The authors examined energy consumption in relation to scheduling algorithms. Table 1 summarizes the main features and aims of existing surveys. Table 2 also compares our review with other reviews based on various issues. Except for one review, all task scheduling algorithms have failed to address QoS metrics. The authors did not mention a fuzzy-based scheduling algorithm. Research on task scheduling using fuzzy systems needs to be reviewed comprehensively to keep up with the latest developments.
The following requirements motivated this article:
-
Task-resource mapping algorithms are in great demand in distributed environments. The use of fuzzy-based approaches in distributed environments is crucial for managing uncertainty and dynamic behavior.
-
Identify the benefits and drawbacks of each algorithm under consideration and suggest optimal algorithms based on the conditions. Algorithm selection is crucial to ensuring that consumers and providers are satisfied.
-
Making a decision based on available data is possible with fuzzy logic.
-
Identify the challenges of fuzzy logic. Due to the inherent flexibility of fuzzy rules, the development and analysis of fuzzy rules is a complex process.
-
Choosing the best simulator depends on the specific scenario, for example implementing cost-aware task-to-resource mappings or the makespan approach.
-
Identifying open challenges and future research directions in this field is necessary.
1.2 Paper organization
Figure 1 illustrates the structure of the study succinctly.

The study’s structure
This paper is structured as follows: Sect. 2 explains distributed systems, grid, cloud, and fog computing, scheduling, and fuzzy inference system. Section 3 describes the research methodology. Section 4 describes a taxonomy of fuzzy-based scheduling algorithms. Section 5 compares these algorithms. In Sect. 6, future research directions are discussed as well as some open issues. Section 7 presents the conclusion.
2 Background
This section presents a brief introduction to distributed systems. In the following, scheduling and fuzzy system are presented.
2.1 Distributed systems
In distributed systems, multiple components are spread across multiple machines and are also called distributed computers. Coordinating these devices creates a sense of cohesiveness for users. Distributed systems are used by computer science (CS) and information technology (IT) to manage complex tasks. However, traditional options lack the advantages offered by distributed systems. Throughout the last 60 years, these systems have evolved. Figure 2 shows the evolution process. Technology and social change have led to a new role for distributed systems. While modern distributed systems enable new markets and artistic expressions, they also present new research challenges to comprehend and improve their operation. Figure 2 illustrates the development process for distributed systems.

A timeline of the distributed systems (Lindsay et al. 2020)
2.2 Grid computing
Systems can process heavy calculations using a network-based computing model. The combination of various services and facilities enables us to create an advanced system capable of handling heavy computing tasks not handled by a single device alone (Asghari Alaie et al. 2023). Figure 3 shows the layers of grid computing:
-
User Interface: The interface simplifies users’ search of the network.
-
Security: This computing environment relies heavily on the Grid Security Infrastructure (GSI). Performing network operations requires OpenSSL.
-
Scheduler: Multiple specific tasks can be run simultaneously with the help of a scheduler.
-
Data Management: The management of data is one of the most crucial aspects of any system or network. Through Globus Toolkit, grids can access secondary storage in a secure, trusted way.
-
Workload & Resource Management: When running on a network, an application must be aware of network resources in order to launch work on them and check their status.
Fig. 3 
The grid computing layers (Guo et al. 2022)

2.3 Cloud computing
Distributed systems commonly use cloud computing. Cloud computing makes it possible to create remote networks, service providers, storage facilities, and applications. Using resources that are configurable and common, this is possible. This model allows customers to easily scale IT services via the internet (Pradhan et al. 2022). Figure 4 illustrates the four layers of cloud computing. Infrastructure as a Service (IaaS) component is one of the most important aspects of cloud computing. In computing, renting an infrastructure means paying for only what you use (e.g., Microsoft Azure). In this layer, you can access hardware, software, networks, and storage. Platform as a Service (PaaS) provides resources for building applications. This layer includes tools for developing and managing databases. Software as a Service (SaaS) consists of a software solution that users can connect to via the Internet and rent from companies and organizations. As a result of cloud top layering, a company’s business functions are outsourced. Customer service, salary management, human resource management, and accounting are all part of these processes.

The cloud computing layers (Masdari et al. 2017)
2.4 Fog computing
Cloud computing processes data more slowly than fog computing. There are nodes in the fog, which are devices (Kumari et al. 2022; Li et al. 2019). Nodes can also have Internet access, computing power, and storage as well as be any device with these capabilities. It is possible to use vehicles or workplaces as target points. Communication between IoT devices generates IoT data through a network (Javanmardi et al. 2021). The data is stored and processed by a cloud data transfer center. Fog computing environments are more geographically distributed and closer to end users, as shown in Table 3.
Fog computing is primarily used to reduce latency. Furthermore, this approach is capable of real-time analytics and functional reductions. It is generally considered that fog computing is the best solution for organizations that require quick data analysis and response. Several IoT applications can be implemented using this approach thanks to the high speed of information transfer and processing. Due to the large amount of data generated by IoT devices, it is time-consuming and expensive to transfer IoT data to data centers. It is greatly simplified to solve this problem with fog computing (Guerrero et al. 2022).
2.5 Scheduling process
Scheduling problems are typically NP-hard. Finding the right solution within a short and adequate period is sufficient. Most optimization problems require a variety of solutions (Mor et al. 2020).
Figure 5 shows a clear relationship between fog, grid, and cloud layers. Clouds are at the top, fogs are in the middle, and grids are at the bottom. Centralized systems consist of a central node that delegate tasks to other nodes. This node is called the primary node. In addition to the workers, there are also delegated nodes. Due to the fact that nodes may function as either primary or worker nodes simultaneously, primary/worker relationships are less clear in distributed systems. The primary nodes must communicate with each other in order for the system to succeed. Hierarchical distributed systems fall into the third category. In hierarchical distributed systems, predecessors and successors are not able to communicate. The scheduler’s scope can vary depending on the architecture.

The relationship between cloud, fog, and grid (Yu et al. 2022)
It is important that schedulers take into account other factors besides the architecture connectedness of primary, workers, and resources. Worker access to network and physical resources is restricted in a cloud computing environment. A scheduler on any operating system can perform the same functions as a scheduler in this program. It involves multiple stages to schedule tasks for primary workers. Global schedulers allow workers to be assigned all tasks. On both primary and worker nodes, local schedulers can schedule incoming and outgoing tasks. The organization of dynamic events is crucial to system efficiency. Typically, global schedulers allocate resources and tasks in centralized distributed systems (Houssein et al. 2021; Islam et al. 2021; Mohammad Hasani Zade et al. 2022). Figure 6 shows a comparison of fog, clouds, and grid.

Challenges associated with cloud, fog, and grid computing (Zahoor et al. 2018)
Different types of schedulers are available, including schedulers for resources, workflows, and tasks.
Resource scheduling: Virtual resources are shared among physical machines (PMs) and servers (Yuan et al. 2021). Prioritizing activities is determined by QoS variables. In on-demand scheduling, random tasks are scheduled rapidly with resources. Performance can degrade when multiple processes run on the same machine, and overprovisioning may result from uneven workload allocation. The under-provisioning of VMs can occur if they are held for a long time. As a result of over-provisioning and under-provisioning, service delivery costs increase. The provisioning algorithm must be able to efficiently assess and handle impending workloads. Managing resources in cloud computing is challenging due to heterogeneity, dynamicity, and dispersion (Murad et al. 2022).
Workflow scheduling: To develop an effective and comprehensive workflow management strategy, a variety of computationally complex programs must be used. Workflows are scheduled by executing interconnected tasks in a particular order (Dong et al. 2021). The number of task nodes in one workflow can be very large, especially when heterogeneous workflows are involved, resulting in many changes in parallel computing needs. It is impossible to solve the workflow scheduling problem because it is NP-complete (Javanmardi et al. 2023).
Task Scheduling: By using this method, tasks can be assigned to resources for implementation. Schedule tasks easier than workflows. In centralized task scheduling, one scheduler can schedule multiple tasks across multiple systems simultaneously. When tasks are scheduled centrally, it is hard to scale and tolerate failures. Task schedulers communicate by using a network (Raju and Mothku 2023). In the cloud system, all tasks sent by users are handled collectively by the schedulers. Consequently, several planners handle the workload, resulting in a considerable reduction in the cycle time (Pradeep et al. 2021). Figure 7 illustrates the scheduling of resources, tasks, and workflows.

The diagram of scheduling process
There are two types of task scheduling processes: static and dynamic. Static scheduling algorithms are used to solve offline scheduling problems in distributed hard real-time systems (Verhoosel et al. 1991). Dynamic schedules are determined during execution based on information currently available, whereas static schedules are fixed before execution. Figure 8 shows the process of static and dynamic task scheduling.

An overview of static and dynamic task scheduling stages (Bansal et al. 2022)
The resource manager manages virtual machines uniformly and determines the speed of computing. Users can submit tasks to the cloud system. A task manager sends tasks to cloud systems, where they are batch processed and the task size is collected. A scheduler begins working once the resource manager and task manager send it information. Figure 9 shows an overview of the scheduling mechanism.

Scheduling mechanism structure (Pang et al. 2019)
Grid scheduling depends on resource allocation and coordination for efficient task execution. Grid services allow applications to create tasks for individuals or Virtual Organizations (VOs). Increasing cloud adoption drives enterprises to adopt cloud computing solutions. Virtualized computing resources can be accessed via cloud computing services without technical knowledge. Table 4 compares grid computing and cloud computing.
Green computing and utility computing have introduced new optimization objectives and variables that could be used in cloud computing infrastructures (Bharany et al. 2022; Kaplan 2005). Several scheduling algorithms were proposed in the early days of grid computing, and many of them were adapted for distributed computing as a result. Various virtualized resources, user demands, workloads in data centers, and changes in resource capacity can all contribute to a cloud having dynamic properties. It becomes increasingly important to schedule tasks as the number of cloud clients grows. It becomes more agile by dynamically allocating and de-allocating a large number of resources. Cloud computing scales up and down as computing resources are added or subtracted. In addition to automatic scaling, dynamic routing, function as a service (FaaS), and resource allocation as a service (RaaS), dynamic cloud services can be used in many ways. Within the past decade, the scheduling literature has grown exponentially as a result of the introduction of new optimization objectives. The field expanded in a way that made assessing new findings difficult. Scheduling tasks in a cloud environment is therefore different from scheduling in a traditional environment.
Fog computing enables cloud computing platforms to handle IoT applications at the edge of networks. The proximity of computing resources to IoT devices makes fog computing a fast way to process IoT requests. The provisioning and management of fog computing resources are among the greatest challenges. Fog computing resources are limited by their capacity limitations, their dynamic nature, heterogeneity, and their distributed nature. It is critical to provide and manage resources efficiently in fog computing in order to implement IoT applications efficiently. Cloud computing provides IoT devices with computing resources that can be accessed quickly and efficiently, allowing for faster processing of IoT requests (Mokni et al. 2023). It is possible to process IoT applications using fog computing, but provisioning and managing fog resources are challenging. It’s difficult to estimate the capacity of fog computing resources since they’re dynamic, heterogeneous, and distributed. It is essential to understand fog computing resource provisioning and management so that IoT applications can take full advantage of fog computing’s capabilities.
2.6 Fuzzy inference system (FIS)
Fuzzy logic (FL) was developed by Lotfi Zadeh (1965). The degree of membership in a universe is usually indicated by a real number between 0 and 1. Fuzzy degrees of truth logic emerge as propositions are assigned truth degrees. It is the real unit interval that gives the typical set of truth-values, corresponding to 0 for “totally false”, 1 for “totally true”, and the other values for partial truth. Fuzzy logic involves modeling logical reasoning by modeling imprecise or vague statements. Logic uses truth values to describe degrees of truth, and this is a category of logic with many values. Fuzzy rules are used to adjust the effects of certain factors in fuzzy control systems. A fuzzy rule-based system typically replaces or substitutes skilled human operators (Mehranzadeh and Hashemi 2013; Nanjappan et al. 2021; Javanmardi et al. 2020; Kumaresan et al. 2023). An inference engine that uses fuzzy rules can be used by a scheduler to make online decisions that maximize system performance based on current network conditions.
FIS is based on a simple concept. These stages include input, processing, and output. Membership functions are created from inputs at the input stage. As a result of the processing stage, each appropriate rule is invoked and a corresponding result is generated. After that, it combines the results. At the end of the process, an output value is produced based on the combined results (Fahmy 2010). A fuzzy system is commonly used in situations where several factors cannot be accurately predicted or known in advance. Fuzzy logic controllers have the advantage of requiring less mathematical modeling than conventional control strategies. Further, fuzzy inferences are suitable for a variety of engineering applications since they map real variables to nonlinear functions. Additionally, fuzzy logic is easy to implement, as it allows for great flexibility in workflow scheduling, for example, where rigor is not required.
A fuzzy logic controller adjusts the parameters of a controlled system based on its current state. There are several steps involved in the design of fuzzy control systems. Inputs and controls need to be identified first. It is necessary to quantify each variable. Afterwards, each quantification is assigned a membership function. Fuzzy rule bases are developed based on input conditions that determine what controls should be implemented. Formulas based on implication are used to evaluate rule bases. Fuzzy outputs can be created by aggregating the results of the rules. The rules of computer computation are much stricter than those of fuzzy theory. The fuzzy theory is useful for a wide range of control problems. It is fundamentally strong since it does not require exact input. In fuzzy theory, knowledge is examined using fuzzy sets. Language expressions such as “Low”, “Medium”, and “High” can be used to show tease sets. Figure 10 illustrates the construction process in four steps.

Fuzzy system steps
Fuzzy set theory is useful for describing imprecise or vague data. The fuzzy logic-based approach is beneficial for solving online and real-time problems because it has a low computational complexity. Mamdani systems and Sugeno systems are supported by Fuzzy Logic Toolbox software (https://www.mathworks.com/help/fuzzy/types-of-fuzzy-inference-systems.html). The Mamdani’s method is usually recognized as a method for containing professional knowledge (Singla 2015; Machesa et al. 2023).
The knowledge can be illustrated more human-like to facilitate better understanding. Fuzzy inference of the Mamdani type requires substantial computing power. For dynamic nonlinear systems, the Sugeno method is incredibly efficient for optimization and adaptive control. The Sugeno method of fuzzy inference was introduced by Takagi and Sugeno in 1985. The fuzzy system can be adapted to model the data more effectively with these adaptive techniques. FISs based on Mamdani and Sugeno methods differ primarily in how crisp outcomes are generated. With a mamdani-type FIS, crispy outcomes are calculated by defuzzing fuzzy outcomes, while with a Sugeno-type FIS, crisp outcomes are calculated by weighing fuzzy outcomes (Kaur and Kaur 2012). The Sugeno FIS does not interpret Mamdani results when their outcome is not fuzzy (Haman and Geogranas 2008). Despite the reinstatement of defuzzification, Sugeno’s weighted average improved processing speed. In decision-support applications, Mamdani-type FISs are commonly used because of their interpretability and perception. As opposed to Sugeno-type FISs, Mamdani-type FISs use a different membership function. As Mamdani FISs cannot be integrated with adaptive neurofuzzy inference systems, their design flexibility is limited. Figure 11 illustrates Mamdani and Sugeno models.

The components of Mamdani and Sugeno model
In Figs. 12 and 13, fuzzy logic is discussed in terms of its advantages and disadvantages. Figure 14 shows how fuzzy logic can be classified into functional fields. In distributed systems (e.g., cloud computing and fog computing), fuzzy logic is often combined with other models to optimize resource usage, balance load, schedule, etc. Table 5 summarizes various fuzzy logic methods. In distributed computing, fuzzy theory methods can be used in different categories (e.g., task and resource management, trust management, healthcare service, and etc.). This paper focuses on task scheduling, since most studies focus on resource management.

Advantages of fuzzy logic

Weaknesses of fuzzy logic

Applications of fuzzy theory
The technology behind resource scheduling is expected to meet users’ demands today. It is common for users to lack the skill to accurately submit their CPU, bandwidth, and storage requirements, but their task attitude can contribute to fuzzy requirements. A cloud computing friendly system aims to meet users’ imprecise needs, and senses these needs in order to satisfy them. Additionally, it is an important standard for quality of service (QoS) in computing environments. Through virtualization, CPU, memory, and GPU resources can be shared by multiple users simultaneously. Resource scheduling is necessary for considering the overall allocation of resources. Resource allocation must also maximize the benefits of all resources. Several characteristics can be used to schedule cloud computing resources so that they meet users’ needs. User resource needs can be predicted due to the long-term nature of cloud computing demand. As a result, fuzzy logic theory can be applied to resource scheduling to solve the extra difficulty caused by imprecise user needs. The combination of fuzzy logic and logical reasoning can make cloud computing systems human-friendly. Dynamic scheduling of resources can be optimized by using feedback control. Dynamically adjusting the configuration can optimize the performance of a resource according to the user’s needs and the resource’s current performance (Chen et al. 2015). In addition, a fuzzy set can also be used to prioritize queued tasks using fuzzy rules (Tsihrintzis and Virvou 2021; Pezeshki and Mazinani 2019; Talpur et al. 2022). Guiffrida and Nagi (1998) summarized four of the most important reasons why fuzzy set theory is relevant to scheduling in Fig. 15.

Motivations of fuzzy theory in scheduling
3 Research methodology
This section provides an overview of fuzzy-based task scheduling methodologies through a Systematic Literature Review (SLR). For gathering task scheduling algorithms, SLR generally includes research guidelines and detailed literature reviews. Figure 16 illustrates several steps involved in research methodologies.

Research methodology
3.1 Data selection source
A thorough search was conducted in three famous scientific databases (i.e., ScienceDirect, Springer Link, and IEEE Xplore) for sufficient and recent information about fuzzy-based scheduling algorithms. Table 6 lists electronic databases as sources of data selection. Different papers between 2005 and 2023 are downloaded in order to conduct this research.
3.2 Study selection procedure
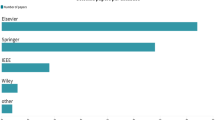
Research on this topic began in March 2022. In every research process, relevant papers must be found. Researchers use keywords related to the research topic to identify and find relevant papers and to filter out those that are unrelated, which greatly influences the content of published papers. A comprehensive search of scientific journals and conferences was conducted to find research papers regarding task scheduling in cloud, fog, and grid environments (see Sect. 3.1). To conduct the search, fuzzy, scheduling, task scheduling, fuzzy logic, cloud, grid, and fog are used. In Fig. 17, we reviewed the selected databases (i.e., IEEE, Springer, and Elsevier) in order to conduct our research. Research papers were collected based on the keywords.

Study selection process
4 Research questions and their motivations
In this study, fuzzy-based scheduling algorithms and techniques are explored in cloud, fog, and grid environments. Table 7 summarizes the different research questions generated by our study. It is imperative that researchers understand the limitations, issues, and challenges associated with existing scheduling algorithms in order to develop effective algorithms.
Researchers will gain a better understanding of fuzzy-based scheduling in distributed systems by answering the above research questions. Table 7 shows an answer to each research question in each section.
5 Review of fuzzy-based scheduling algorithms
This section introduces 35 fuzzy logic-based scheduling algorithms for cloud, fog, and grid systems. This collection includes papers compiled from a variety of peer-reviewed sources. These papers examine fuzzy-based scheduling algorithms for clouds, fogs, and grids between 2005 and 2023. For the last 18 years, we calculated the number of publications per year to visualize research evolution. We divide fuzzy-based scheduling algorithms into three categories: (i) fuzzy-based scheduling algorithms in the cloud environment (ii) fuzzy-based scheduling algorithms in the fog environment and (iii) fuzzy-based scheduling algorithms in the grid environment.
Figure 18 shows that cloud computing was used in 43% of papers, grid computing in 34%, and fog computing in 23%. Cloud computing is a system that communicates via remote servers and hardware. There are two types of processors: servers and local processors. The fog technology allows data to be offloaded to the cloud more efficiently while storing, processing, and analyzing it. Fog computing differs from cloud computing in that it is distributed and decentralized. Fog network provides information as close to the source as possible as a complement to cloud computing. There are many similarities between cloud and fog concepts. Although cloud computing differs from fog computing in some important ways, there are some similarities as well.

Various environments with fuzzy-based scheduling algorithms
Figure 19 shows a visualization of keywords. This chart can be used to learn more about the most important keywords for this topic. Depending on the frequency, each word has a different size.

Keywords frequency in reviewed articles
5.1 Fuzzy-based scheduling algorithms for cloud
Xiaojun et al. (2015) classified cloud computing resources according to Resource Scheduling Based on Fuzzy Clustering Algorithm (CBFCM—Cost-based Fuzzy Clustering Algorithm). This study analyzes four scheduling algorithms, as well as the resulting resource scheduling scheme. A virtual machine's resources are monopolized by each task. It is desirable to schedule job tasks as parallel as possible, in order to avoid task blocking, and to minimize the amount of time it takes to run the job. There are many resources available for computing, including networks, servers, storage, applications, and services. This approach allocates cloud computing resources at the user level using a parallel labor cost performance model, and platform-level resources using fuzzy clustering. The results indicated that the algorithm's number of iterations and classification accuracy are reasonable.
Zhu et al. (2020) proposed Fuzzy Dynamic Event Scheduling (FDES) for scheduling periodic multistage jobs. It uses two metrics (i.e., cost and satisfaction). A high degree of satisfaction is achieved by combining the VM Availability Maintenance (VMAM), Task Collection Strategies (TCS), task deadline assignment (TDA), and Fuzzy Task Scheduling (FTS). Virtual machines in virtual clusters can be maintained through time slot maintenance. To determine which tasks should be scheduled, two TCS proposals have been proposed: (1) The TCS1 proposes only to schedule tasks that have arrived since the last scheduling period. (2) TCS2 replaces unfinished tasks from the previous time window with just arrived ones. It performs two main operations: task prioritization and task allocation. The priority of ready tasks is assigned during task prioritization, and the fuzzy priority is assigned during task allocation. A fuzzy minimum heap will be used to prioritize ready tasks. Triangular fuzzy numbers represent fuzzy temporal parameters. In addition to being completely reactive, dynamic scheduling considers three aspects: (1) jobs arrive at unpredictability; (2) data transmission times are uncertain between any two consecutive tasks until completion of data transmission; and (3) the processing time for a task is uncertain until it has been completed. A comparison of FDES to DES and Heterogeneous Earliest Finish Time (HEFT) algorithms indicates that it performs more efficiently and robustly than other algorithms.
Using fuzzy quotient space theory, Qi and Li (2012) presented a cloud job scheduling algorithm. Resources can be scheduled by abstracting computing attributes into virtual machines. To assign weights to virtual machine attributes, minimum variance mean theory is used. Consequently, multi-attribute information is granulated based on user QoS requirements. Three indices are used to describe the problems (X, f, T), where X denotes the conceptual set, f (.) denotes the attribute of X, and the structure of X and the relationships between its elements are represented by T. The first step is to coarsen the granulation space, construct candidate collections, and meet task execution requirements. QoS factors are used to classify tasks and fuzzy quotients are used to define distance functions. Experiments indicated that the algorithm performs user tasks efficiently and effectively.
According to Farid et al. (2020), FR-MOS is a new method for scheduling scientific workflows that combines Fuzzy Resource Utilization and Multi-Objective Scheduling (MSO). The provider offers several machines to users. PSO schedules a real scientific workflow in a multi-cloud environment. It is important to minimize costs and time as much as possible. Four QoS requirements are considered in the FR-MOS algorithm, including the makespan, the cost, the reliability, and the resource utilization. Users need to create an application structure before starting a workflow application. Cloud platforms should support VM types compatible with workflows. Cloud providers assign tasks to task queues, and tasks are handled based on workflow structures. The cloud provides a limitless number of virtual resources, but task sequencing must depend on each other since tasks can be queued in parallel. In the FR-MOS algorithm, the reliability coefficient ρ is determined by fuzzy logic.
Guo (2021) proposed a fuzzy self-defense algorithm based on multi-objective task scheduling. Furthermore, the load balancing algorithm considers the customer's waiting time and task costs. It is necessary to schedule multi-objective tasks in cloud computing in order to minimize waiting times for customers. Furthermore, multi-objective task scheduling considers the cost of multi-objective task completion as well as resource load balance. By using this method, schedule completion times can be reduced, improving schedule efficiency. According to the estimates, 95% of the resources were utilized, which is a reasonable rate.
Mansouri et al. (2019) proposed a hybrid task scheduling algorithm named Fuzzy Modified Particle Swarm Optimization (FMPSO) that is based on the fuzzy system. FMPSO incorporates speed updates, crossovers, and mutations along with roulette wheels. The SJFP method starts with the construction of a population, followed by the calculation of velocity matrices, position matrices, crossover operators, and mutation operators. Scheduling strategies are based on three common assumptions. In the first place, all tasks are independent. A user submits n tasks for execution across m virtual machines to minimize execution time and to optimize resource management. Virtual machines are scheduled in first-come-first-served order if there are more tasks than virtual machines. Virtual machines are assigned tasks according to the proposed scheduling strategy (FMPSO). Transferring tasks between virtual machines is not possible. It is not allowed to assign one task to multiple virtual machines at the same time. Fuzzy inference considers inputs such as task lengths, CPU speeds, RAM sizes, and execution times when calculating fitness. POS is further optimized through crossovers and mutations. In the experiment, FMPSO used resources more efficiently.
Zhou et al. (2018) proposed a method for workflow scheduling in Infrastructure as a Service (IaaS) called Fuzzy Dominance Sort based Heterogeneous Earliest-Finish-Time (FDHEFT). An algorithm based on HEFT (Heterogeneous Earliest-Finish-Time) scheduling lists and fuzzy storing is proposed. It begins with an overview of HEFT and HEFT-based algorithms, followed by a description of fuzzy dominance sort, and ends with a discussion of FDHEFT. The HEFT method uses a list-based heuristic to prioritize tasks and select instances. Priority-based selection is performed by HEFT according to the priorities assigned to each task. Each selected task is assigned to its best instance based on its priority and minimizes completion time by selecting tasks in order of priority. Multi-objective performance is measured using fuzzy dominance sorts. For multi-objective problems, the FDHEFT allows them to explore high quality tradeoff solutions and achieve fast convergence. The task prioritization process consists of two phases: task selection and instance selection. The higher rank tasks in a workflow are prioritized based on FDHEFT's upward sorting by non-increasing rank values. By using fuzzy dominance values, FDHEFT sorts and selects the best K schedule solutions in the instance selection phase. Workflows in IaaS clouds should be more cost-effective and faster. The resource parameters and pricing of Amazon EC2 facilitated FDHEFT's cost effectiveness and time reduction.
Samriya and Kumar (2020) presented an optimal Service Level Agreement (SLA) based task scheduling by hybrid fuzzy TOPSIS-PSO (Particle Swarm Optimization). PSO-based algorithms optimize available tasks and VMs. In cloud computing, task scheduling is a challenging issue due to the large number of users. This paper presents an algorithm for scheduling tasks to solve these problems. Fuzzy TOPSIS and PSO algorithms are used in this study in order to plan productively the task in cloud. This study seeks to reduce energy consumption and migration costs. A multi-objective function is achieved by hybridizing PSO with Fuzzy TOPSIS. PSO optimizes the number of virtual machines and the available tasks at the beginning. As an objective function, Fuzzy TOPSIS uses the weighted sum of energy, cost and execution time to solve the multi-objective task scheduling problem. With the Fuzzy-TOPSIS algorithm, the task scheduling problem is solved for cloud-based SLA-based tasks by estimating the cost, energy weight, and execution time of each task. Experimental results showed that the proposed algorithm meets the SLAs, facilities, and QoS requirements.
Wang et al. (2022) proposed that a task scheduling framework based on locality, deadlines, and resource utilization is an energy-efficient one. Tasks are scheduled to rack- and cluster-local servers, as well as remote servers, in order to achieve high levels of data locality. A cluster slot is updated once tasks and slots are assigned. A fuzzy logic algorithm optimizes server CPU, memory, and bandwidth utilization. Fuzzy logic dynamically configures CPU, memory, and bandwidth on each server. The Jiangsu Institute of Public Security Science and Technology provides the data necessary to construct three membership functions. It is possible to derive fuzzy rules using practical operators. The calculation of dynamic server slots is possible using fuzzy logic constructs based on practical data. Each job consists of several independent tasks and is completed at time 0. Servers are shared among clusters for MapReduce jobs. Each job has an assigned number of servers. Job processing requires the use of physical servers. Using MapReduce clusters with variable number of slots, energy consumption was reduced while staying within deadline constraints (U - T1). Based on experiments, the proposed task scheduling significantly reduced energy consumption.
Shojafar et al. (2014) presented a hybrid approach that is based on fuzzy theory and a Genetic Algorithm (GA), which is called FUGE. FUGE algorithm assigns tasks based on the performance of virtual machines and memory. FUGE enhances GA using fuzzy theory. Two types of chromosomes are proportional evaluated using QoS parameters. First-generation output chromosomes undergo a modified fuzzy operation before being added to the population. One of the best chromosomes from the first generation is called the output chromosome. These criteria serve as input parameters for fuzzy systems. There is no limit on the number of chromosomes each type should have, but they should have the same number for both types of chromosomes. Each chromosome of each type is then allocated computational resources (standard random) in order to calculate the fitness value. For every gene (job), fitness function values are added to calculate chromosome fitness functions. The fitness value of each chromosome determines which is selected. Summing the fitness function values of chromosomes' genes yields the fitness function values for those chromosomes. The algorithm generates a new chromosome based on the overlapped chromosomes (of different types) and performs the crossover operation on those selected chromosomes. The best chromosome of the first generation (i.e., the best chromosome of the first generation) is created after completing this step. The first generation is regenerated after adding this chromosome back. Recursively repeating the entire process for the new population is referred to as the recursive algorithm. Simulations by FUGE showed it was possible to achieve an effective load balance at an affordable cost.
By applying the fuzzy dominance mechanism, Rani and Garg (2021) improved the application's reliability while reducing energy consumption, using the Reliable Green Workflow Scheduling (FDRGS) algorithm. Fuzzy dominance sorting machines determine the optimal trade-off solution based on the fuzzy dominance values. There are two phases to the algorithm. The first step in creating a workflow application is assigning a rank to each task. Consequently, the tasks ranked highest within the workflow application are given priority. Secondly, each task is assigned to the appropriate processor. They sort the trade-off solutions using fuzzy dominance. It determines the best compromise by comparing trade-off solutions. In addition to optimizing energy consumption, dynamic voltage and frequency scaling (DVFS) is used to select a specific processor frequency level to ensure task reliability. A further benefit of the DVFS approach was that it could save energy. An analysis of the performance of FDRGS is conducted compared to the performance of ECS (Energy-Conscious Scheduling), HEFT, and RHEFT (Reliable-HEFT) algorithms. In terms of energy usage and reliability, the proposed algorithm performed better.
Gholami Shooli and Javidi (2020) proposed a Gravitational Search Algorithm (GSA) with a fuzzy system for resource allocation and task scheduling. It is also possible to solve nonlinear problems using GSA. The four main forces of nature can be divided into four categories. In addition to gravity, weak forces and electromagnetic forces also exist. In the universe, three forces act, but gravity is the strongest. GSAs optimize discrete time artificial systems using gravitational laws and motions. The first step involves determining the system space. In the problem space, there is a multidimensional coordinate system. The problem can be solved by any point in space. Masses make up the search agents. Generally, a mass can be described in terms of its position, gravity mass, inertia mass, and inertia mass. There are several factors that determine a mass's gravitational and inertial masses, including its fitness. The rules of the system are established after the system is formed. In this assumption, only gravitational laws and motion laws will be established. To achieve the solution, a random position is assigned to each mass in the algorithm. Every time a mass is evaluated, its position is determined. Furthermore, the mass of gravity, the mass of inertia, and the Newton gravity constant are updated continuously. Repeatability is a good indicator of the stop condition. When GSA calculates the number of masses, it uses a fuzzy system. It minimizes makespan, flow time, and load imbalance during task assignment. In experiments, the approach algorithm seems to efficiently allocate resources, balance loads, and save time.
In Soma et al. (2022), Soma et al. proposed a Pareto-based Non-dominating Sorting PSO (NSPSO) method for optimizing multi-objective problems. Users can select a dynamic configuration based on their needs. It is possible to make sense of uncertain situations using fuzzy logic. Statistically, non-dominated solutions are likely to be more prevalent in large-scale scientific applications; memory usage is another objective when determining the quality of a solution. Moreover, fuzzy rules simplify the process of classifying solutions, allowing users to make quicker decisions. It is possible to select the best resource pair and task pair based on user preferences with the NSPSO fitness function when fuzzy based decision selection is incorporated. This system aims to accomplish the following: (1) Optimizing workflow tasks with a multi-objective approach to minimize energy and time consumption. (2) The above problem can be solved by using NSPSO meta-heuristics based on Pareto and Fuzzy Rules (F-NSPSO). (3) Compared to Simple DVFS, NSPSO, and other algorithms, the F-NSPSO algorithm performs better. F-NSPSO performed real-world scientific applications for Epigenomics, Cybershake, and Montage using varying task sizes. In comparison with DVFS, F-NSPSO performs better.
One of the major challenges in the Internet of Things (IoT)-Cloud scenario is uploading and replicating data across multiple cloud data centers. The number and location of replicas can be determined adaptively, avoiding this problem. Despite the fact that data replication ensures reliability and availability, many copies of each data will require more storage space. This problem can be overcome by replicating the files a minimal number of times. Saranya and Ramesh (2023) studied IoT-Cloud data replication and scheduling using a hybrid fuzzy-CSO algorithm. It finds the best replication locations using Cat Swarm Optimization (CSO). The authors presented a data collection network based on Fuzzy-CSO algorithm's common framework for IoT-Cloud. The fuzzy-CSO algorithm optimizes replication locations. Data replication is scheduled at selected replication points by a task scheduler. The cloud is used for uploading uncompromised data once it has been isolated. Data can be requested using the request-response method. Reports can be generated using the collected data that day or average reports can be requested based on collected data. Fuzzy logic models consider fault occurrence probability, energy costs, and storage capacity when determining how many replicas to use. Fuzzy logic decision returns the optimal number of replicas. It transfers data faster, responds faster, and maximizes bandwidth utilization compared to existing algorithms.
Since workflow scheduling often occurs in uncertain environments, most studies avoid rigorous conditions without fluctuations. A workflow fuzzy scheduling algorithm (WFSA) is presented by Ye et al. (2022). By using the fuzzy sorting strategy, WFSA ranked tasks according to their processing time using triangular fuzzy numbers (TFNs). The fuzzy deadline assignment method is developed using partial critical paths (PCPs) of workflows that are used to decompose workflow deadlines into task sub-deadlines. It presents a workflow scheduling strategy based on heuristics that is cost-driven and meets task deadlines. In comparison with other benchmark solutions, the algorithm reduces workflow execution costs effectively.
Table 8 summarizes the cloud environment proposals and analyzes them. Table 9 summarizes cloud scheduling algorithms. Table 10 compares cloud scheduling algorithms based on QoS parameters.
5.2 Fuzzy-based scheduling algorithms for fog
Ali et al. (2021) presented a task scheduling algorithm for fog-cloud computing that uses fuzzy logic. Assigning tasks to appropriate processing modules creates a haze layer that operates on heterogeneous resources. Additionally, other factors (such as time and size of data) are considered. In the haze layer, custom real-time tasks can be executed to improve IoT application performance. To determine the best place for processing a task, the fuzzy decision algorithm considers resource requirements, time constraints, maximum fog layer resources, cloud-to-fog latency, and maximum fog layer resources. A task cannot be carried out on the fog layer, so it is passed to the cloud. Resources are normalized instead of being calculated and calculated. A Fuzzy Logic Based Decision Algorithm determines whether to process a task in the cloud or in the fog based on the task's resource utilization, deadline, and network latency. When a task is assigned to a fog layer, it is added to the fog queue FQ. The fog queue is ordered according to the deadlines of the tasks. Thus, more tasks will be completed within deadlines by completing urgent tasks with hard deadlines first. The proposed algorithm is faster in construction, has a lower latency rate, and has a shorter rotation time than other algorithms.
Benblidia et al. (2019) proposed a ranking-based task scheduling system based on user preferences and fog node characteristics. Nodes are ranked according to their satisfaction with fuzzy quantified propositions. A major contribution to the paper is the application of fuzzy logic to task scheduling, and the refinement of scoring with two metrics Least Satisfactory Proportion (LSP) and Greatest Satisfactory Proportion (GSP). In the fog network, low-power terminal devices handle requests from high-performance users. A fog node receives requests through a wireless network (e.g., LoRa, WiFi, or Bluetooth). Fog nodes distribute requests via task schedulers. In addition to analyzing data summaries, the cloud also sends new application rules to fog nodes, which implement the rules. There are five criteria for serving users: distance, price, latency, bandwidth, and reliability. Fuzzy membership functions are generated based on users' preferences. It is based on the user's preferences and the fog node's restrictions on sending requests to the user that a fog node is selected. In the experiments, the proposed algorithm achieved satisfactory levels of user satisfaction while balancing implementation latency and power consumption.
By combining fuzzy-constraints with multi-agent systems in the fog-cloud environment, Marwa et al. (2023) have proposed a fuzzy-cone approach called (Fuzzy-Cone). Multi-agent systems use fuzzy inference to model all possible scenarios, which facilitates decision-making. The workflow scheduling problem is modeled using a Fuzzy Constraint Satisfaction Problem (FCSP). In a win–win situation, the client agent represents the client, while the supplier agent represents the supplier. Each agent models a set of fuzzy constraints based on its negotiations by making offers or counter-offers. It represents the imprecise preferences of the approach entities by using predefined fuzzy constraints that ensure compliance with all restrictions. Compilation time and cost of the workflow scheduling solution are optimized. Scheduling workflows is optimized by reducing compilation time and increasing costs.
Vemireddy and Rout (2021) introduced the Fuzzy Reinforcement Learning algorithm (FRL). Whenever task deadlines and resource availability limit mobile fog nodes, they offload tasks using fuzzy reinforcement learning. Using Vehicular Fog Computing (VFC) frameworks and Fuzzy Reinforcement Learning (FRL), an energy-efficient task allocation is achieved for fog-breaker vehicles. It is possible to accelerate algorithm learning through fuzzy logic. Vehicle weights are calculated by fuzzy systems based on factors such as processing rate and distance. Each system state is associated with a set of RL actions. Greedy analysis is used until the agent determines the most advantageous actions. A fog vehicle represents a state while a time slot represents an action. Service time and energy are also taken into account when calculating the reward for each RSU. Vehicles cannot be directly identified by the RL agent in a dynamic situation. As a result of its training, it reacts to the weights of vehicles as actions. Reinforcement learning can be used by policy designers to determine which fog vehicle set is most appropriate for their policy. It is important to maintain a balance between the RSU's service time and energy consumption in order to maximize long-term rewards. Based on a comparison with other algorithms, the FRL algorithm uses 46.73 percent less energy and responds 15.38 percent faster.
In fog computing, Wu et al. (2021) proposed an evolutionary fuzzy scheduler to allocate resources to multi-objective applications. With the help of Estimation of Distribution Algorithm (EDA) applications, the fuzzy offloading strategy is determined and optimized. A probability model, P, is developed first, and then individuals are sampled using P. Results are evaluated next. Whenever elite individuals are identified, P is updated accordingly. The updated P value is then used to sample new individuals until the stopping criteria are met. By clustering applications, system resources are efficiently utilized. A number of contributions have been made, including (1) fuzzy logic-based methods of assigning tasks to different layers (2) fuzzy number approaches to modeling and data transfer (3) and performance improvement in fuzzy logic-based partitioning with local operators. They used the nearness degree to compare two fuzzy sets. The proposed algorithm delivers robust performance for Pareto sets according to simulation studies.
Shukla et al. (2020) proposed a method for scheduling multi-objective tasks that is energy-efficient while using interval type-2 fuzzy timing constraints. Embedded Real-Time Systems (RTES) must determine the speed at which tasks are completed in order to be efficient. Energy-efficient scheduling is necessary in these systems. Input parameters are either data- or expert-driven. The proposed method proposes two fuzzy type-2 fuzzy membership function algorithms and two fuzzy type-2 fuzzy scheduling limitation algorithms. Two conflicting objectives must be resolved when scheduling embedded real-time systems: energy efficiency and timeliness. It is possible to model uncertain timing constraints in RTESs by using IT2 FID (interval type-2 fuzzy input data). Energy consumption should be minimized in order to achieve the first objective. It is essential to schedule all tasks in advance in order to accomplish the second objective. Cost functions are used to model each objective. Fuzzy type-2 uncertainty improved efficiency and robustness in RTES.
The Hosseini et al. (2022) algorithm used Priority Queues, Fuzzy Analysis, and Hierarchical Processes in determining routes and scheduling. The first step in weighting criteria is to determine their relationship. Each criteria set is weighted in order to produce a priority list. A top-down priority queue is used to prioritize tasks. This queue should be simulated as a maximum heap queue. Prioritizing tasks assigns resources according to priority. The criteria will also be used to prioritize new tasks. Once the tasks have been assigned, they are executed. It is first determined how long a task will take and how much energy it will consume. Experimental results indicated that the proposed algorithm optimizes service level, waiting time, and number of scheduled tasks on the MFC side.
Rai et al. (2021) described a three-tiered architecture for vehicular fog computing that uses a Road Side Unit (RSU) to coordinate mobile devices and fog vehicles. A chain of vehicles is created and updated periodically as part of the schedule constraint. A fuzzy logic-based task allocation strategy is developed to maximize community value. Experimental results indicated that the proposed algorithm outperforms other existing approaches.
According to Table 11, we can find a summary of the proposals in the fog environment and an analysis of them. Table 12 summarizes fog scheduling algorithms. Table 13 compares fog scheduling algorithms based on QoS parameters.
5.3 Fuzzy-based scheduling algorithms for grid
Zhou et al. (2009) studied Ant Colony Optimization (ACO) and Fuzzy Reputation Aggregation (FR) algorithms to improve scheduling decisions. The proposed algorithm integrates node properties and reputation values, and fuzzifies these properties using fuzzy logic. It is possible to calculate local trust scores and global reputation using fuzzy logic inference rules. Along with three fuzzy variables assigned coarsely to attributes (good, ordinary, poor), five output variables are assigned coarsely to attributes (very good, good, ordinary, poor, very poor). This algorithm is faster when historical and node information is taken into account.
Moura et al. (2018) proposed Int-fGrid to address uncertainty in network environments using Fuzzy Type-2 logic. BoT (Bag-of-Tasks) is assigned to machines according to their execution time. Int-fGrid receives both a BoT and a Current State of Grid Resources as inputs. Int-fGrid determines which machines are available for use based on their current states. Each machine in the system is measured for Communication Costs (CC) and Computation Power (CP), and the data is then adapted to a Standard Scale. The next step is to move on to the Type 2 Fuzzy Module, which includes fuzzy logic fuzzing, inference, and defuzzing. Priority lists will be created based on the analysis of the available machines' priorities. It also verifies that some machines still remain unanalyzed. Priority lists for all the available machines are available, so all the machines must be analyzed before a priority list can be generated. Scheduler Decision Maker maps tasks according to the available machines based on the priorities list. Machines with higher priority receive tasks more efficiently. Tasks are assigned to machines based on their priority. SimGrid simulations showed that the proposed algorithm controlled the extra traffic and intrusions created in the network.
Vahdat-Nejad et al. (2007) presented several fuzzy algorithms to schedule global tasks in multi-clusters and grids. Fuzzy logic matches available resources with job specifications based on job specifications. There are two layers of scheduling: global and local. A global scheduler assigns tasks to clusters depending on their computation and communication requirements. Tasks are evaluated using a two-degree matching system. The suitability of a task depends on the number and level of low-load nodes in a cluster and the bandwidth available to the job. Cluster nodes receive tasks from local schedulers. Schedulers assign jobs to clusters when they arrive. Each cluster is assigned two weights (between zero and one). According to cluster weight 1, jobs require low-load CPUs and a large number of tasks. In addition, cluster weight 2 takes into account job and cluster communication requirements. The scheduler assigns the job to the cluster with the highest priority. Simulation results showed that a low completion time was achieved thanks to the proposed algorithm that considers network traffic during scheduling.
In grid computing, Rong and Zhigang (2005) made use of the Fuzzy Applicability Algorithm (FAA) to schedule meta-tasks. The problem was divided into a number of smaller tasks without communication between them. It is necessary to determine the attributes of resources before scheduling them. A site's communication and storage resources must be adequate before tasks can be executed. To select the maximum number within this set, the FAA selects the most significant number. Therefore, the biggest task determines the tasks and resources. Each time a resource is changed by the scheduler, the solution is output. Task scheduling continues until no more tasks need to be scheduled. In addition to the estimated cost, the practical cost and the estimated execution time are taken into account. Each task is optimized by maximizing the weighted average fuzzy applicability. Even though FAA is the cheapest over the long run, it is more expensive than Max–Min (Mala et al. 2021) and Fast Greedy (Wang et al. 2018).
Salimi et al. (2012) proposed a method to schedule independent tasks in a market-based grid with load balancing based on NSGA II and fuzzy mutations. Parallel distributed computer systems can solve independent task problems using NSGA II and fuzzy adaptive jump operators. Fuzzy mutation prevents mutations from disrupting solutions. The Pareto process can be accelerated and simplified since various reduce mutation rates and prevent disruptions in the solution process. It is important to reduce the time needed to complete a job, load machines, and keep prices low. NSGA II with Fuzzy Adaptive Mutation Operator can be used to solve problem relating to independent task assignment in distributed computing systems. When scheduling tasks in a grid, there are three approaches. This problem is investigated using NSGA II, followed by MOPSO. Then, both NSGA II and fuzzy logic were used to assign two objective functions, Price and Makespan. The optimization of task scheduling is based on three objective function optimization strategies: Price, Makespan, and Load Balancing. Variance between Costs and Gene Variance are inputs for NSGA II with fuzzy mutations, which express differences between bits' values, so that individuals are not equal. It is possible to generate Pareto optimal solutions more quickly and precisely by using this algorithm.
García-Galán et al. (2012) implemented a fuzzy scheduling algorithm based on swarm intelligence. In Fuzzy Rule-Based Systems (FRBSs), knowledge is driven by fuzzy rules and is highly adaptable to changes in the environment. This system illustrates how variables interact within it using Fuzzy-Logic. Swarm Intelligence can also acquire knowledge using FRBS-based scheduling. Variables are used to describe both the current state of machines and the results obtained so far during scheduling. Performance evolution over time is dependent on their actual resource conditions in each domain as well as their actual performance conditions. Scheduling based on fuzzy rules is easier when PSO is adapted to them. Simulated results showed that a fuzzy-meta scheduler outperformed six classical queue-based and task scheduling methods used today. Moreover, 62.6% of fitness training results are generated by the fuzzy scheduler.
Prado et al. (2012) proposed multi-objective knowledge acquisition for the provision of QoS at the grid scheduling level. The Knowledge Acquisition with a Swarm Intelligence Approach (KASIA) implements a new learning strategy using swarm intelligence rules. The performance of an efficient meta-scheduler network is evaluated using well-known GAs and Pareto optimization theory. Because FRBS incorporate both network expert knowledge and grid state uncertainty, they provide efficient solutions. Fuzzy systems consider factors such as tardiness, deadline evaluation, delayed jobs, and lead times when making decisions. As a first step, an objective function or fitness must be improved. The search space is initialized with NP particles distributed randomly. A particle's position is updated through iterations in order to improve objective function f. Particles also lean to maintain momentum in order to achieve optimal results. Additionally, the social component refers to the movement of the particle towards its best position. At the end, the location of a particle changes. Multi-objective fuzzy rule-based scheduling improves network resource optimization.
Salimi et al. (2014) used a fuzzy operator in a network environment in order to improve the performance and quality of the non-dominated sorting genetic algorithm (NSGA-II). Scheduling jobs in a grid environment takes into account three objectives: load balancing, makespan, and price. NSGA-II calculates fuzzy crossover and mutation functions using variance between individuals' costs, variance between resources' frequencies, and variance between genes' values. Searching for Pareto-optimal solutions is simplified with fuzzy operators, which reduce computation and simplify decision-making. The fuzzy method can be used to improve the Pareto front by utilizing adaptive mutation rates along it. Therefore, a fuzzy system is fed both fitness variations of individuals and resource frequency variations. Load balancing is indirectly improved through an additional input combined with a makespan objective. Fuzzy systems determine crossover rates in populations. The proposed approach balances the workload with less repetition to achieve the best results.
Liu et al. (2010) developed an algorithm for scheduling computational grid jobs. Fuzzy matrices represent particle positions and velocity in PSO. A new job is assigned to a machine based on the Longest Job on the Fastest Node (LJFN) method and the Shortest Job on the Fastest Node (SJFN). Scheduling array elements are tagged as “1” in the position matrix, and the remaining numbers are tagged as “0”. It is necessary to process both the scheduling array and the makespan (solution) in order to calculate the scheduling solution. The PSO algorithm is compared with simulation annealing (SA) and GA. Results showed a faster convergence rate and an efficient scheduling process.
In a virtual organization, Prado et al. (2010) presented an application-level genetic fuzzy rule-based scheduling system for scheduling computationally intensive BoT applications. Tasks are arranged and scheduled in a fuzzy manner. AI-based scheduling systems involve several systems: tasks gathering, tasks sorting, and AI-based scheduling. It is initially necessary to identify the points in time, referred to as mapping events, when tasks are incorporated into the objective set of tasks q(t) based on their arrival at the meta-scheduler. A time interval \(\Delta t\) is specified after each mapping event at t. Thus, both tasks that were not scheduled in q′(t) as well as those that arrived after the batch-mode strategy was applied will be included in waiting queue q(t). Moreover, the task sorting system reorders tasks before resource domain (RD) allocation, forming the queue q″(t) properly. During task assignment, the scheduler uses a fuzzy system that takes several factors into account (e.g., amount of memory, amount of CPU time, number of idle MIPS, number of free processors, free memory, size of executed tasks, and number of executed tasks). This strategy improves response times by nearly 11% over other well-established scheduling methods. In addition, it improves response times and balances load while effectively managing users' priorities.
Saleh (2012) proposed an efficient grid scheduling strategy using a fuzzy matchmaking approach. A key focus of researchers is to minimize turnaround times and solve scheduling haste. The first step is to model ready-to-run tasks. Moreover, a fuzzy-based matchmaking method is used for assigning tasks based on CPU power, memory requirements, and storage requirements. In this proposal, grid-scheduling is divided into three tiers, namely: Grid Clients Tier (GCT), Grid Scheduler Tier (GST), and Grid Workers Tier (GWT). GCT represents grid users through their client machines, which they can use to accomplish their tasks. It provides an infrastructure to simulate a virtual supercomputer with GWT. The system aggregates the computational power of geographically dispersed workers. GST is an important component of the proposed scheduling frameworks. Scheduling decisions are made by GST. GST also collects task results and sends them to the task creator. Simulations revealed that the proposed scheduling strategy resulted in a reduction in failure rates and makespan.
Rajan (2020) proposed the FPDSA algorithm for scheduling jobs in grid computing. Using fuzzy time delays, tasks are assigned based on processing speed. For this reason, they estimated the expected execution time using a fuzzy number. By subtracting the deadline from the fuzzy expected computation time, a reverse allocation produces a difference. The resource inventory of a task is determined by its requested properties and the number of processors it requires. The appropriate task should be selected based on the availability and processing speed of scheduled tasks. The dispensation velocity of this system is maximum, so it becomes a priority as soon as it is implemented. It was compared with the Improvised Deadlines Scheduling Algorithm (IDSA), Earliest Deadlines First (EDF), and Prioritized Based Deadlines Scheduling Algorithm (PBDA) according to the average actual execution rate (AAE), non-delayed jobs, and delayed jobs. FPDSA was found to be effective in reducing the number of delayed jobs.
According to Table 14, we can find a summary of the proposals in the grid environment and an analysis of them. Table 15 summarizes grid scheduling algorithms. Table 16 compares grid scheduling algorithms based on QoS parameters.
6 Analysis and comparisons
6.1 Taxonomy based on publishers
The selected articles come from ScienceDirect, IEEE, and Springer publishers. Figure 20 compares the classification of papers by three publishers. As shown in Fig. 20, ScienceDirect accounts for 34% of all papers, IEEE for 40%, and Springer Link for 26%.

Articles based on different publishers
6.2 Taxonomy based on the year of publication
Figure 21 shows the papers categorized by publication year. Among the articles published from 2005 to 2023, most appeared in 2012, 2020, 2021, and 2022.

The distribution of papers based on their publication year
The majority of articles in the grid environment were published in 2012 (see Fig. 22). Cloud and fog papers generally focus on the years 2019–2023. Cloud-based publications dominate in 2020, whereas fog-based publications dominate in 2021.

The distribution of articles based on their publication year in the cloud, grid, and fog
6.3 Comparison based on the type of scheduling method
Figure 23 illustrates the static and dynamic modes of algorithms. Most presented algorithms (about 91%) use dynamic methods, while only 9% use static methods. Table 17 shows that dynamic algorithms are used more often than static algorithms.

Distribution of static and dynamic algorithms
6.4 Comparison based on evaluation environment
Figure 24 shows that a majority of articles used simulation tools to evaluate their algorithms, whereas only one used real-world environments. There have been no papers that use both simulation tools and real-world environments together. Furthermore, two articles did not specify whether a real environment or a simulation tool was used. There are many simulation tools that are used in Cloud, Fog, and Grid computing in order to evaluate new scheduling algorithms. CloudSim (Hicham and Chaker 2016) is a popular simulation tool. Simulators like GridSim (Buyya and Murshed 2003) and iFogSim (Gupta et al. 2017) are also available. Figure 25 indicates the distribution of algorithms using a simulation framework. CloudSim simulator is used by 22% of algorithms, Matlab and GridSim simulators by 16% and 14%.

Evaluation environment

Algorithm distribution by simulation framework
Cloud computing involves simulating the infrastructure and services provided by the cloud using CloudSim. It is entirely programmable in Java and developed by CLOUDS Lab. Modeling and simulating cloud computing environments is used before software development to replicate tests and results. Figure 26 shows that the CloudSim offers several benefits.

CloudSim benefits
CloudSim can perform a variety of simulations and models, as shown in Fig. 27.

Model created using CloudSim
Engineers and scientists can analyze and design systems and products with Matlab. Simulink and Model-Based Design facilitate the deployment and analysis of enterprise applications. GridSim simplifies and automates modeling and evaluating scheduling algorithms. Parallel and Distributed Computing (PDC) simulates interactions between users, applications, resources, and resource brokers. Resource brokers enable the aggregation of heterogeneous resources. The management of these resources is done by different types of shared schedulers, including shared memory, multiprocessors, and distributed memory schedulers. The heterogeneity of a resource depends on its configuration, availability, and processing capabilities. Scheduling algorithms or policies assign tasks to resources based on system or user objectives.
Figure 28 illustrates which simulators were more and less used in each environment by articles. According to this study, GridSim simulation tools are used more commonly in grid computing environments than other tools. CloudSim is the most common tool for simulating cloud environments. Simulations in fog environments are usually performed using Matlab.

Distribution of algorithms by simulation framework and environment
6.5 Classification based on various meta-heuristic algorithms
Figure 29 shows that most algorithms use meta-heuristics along with fuzzy systems when solving scheduling problems. Some articles used traditional algorithms, while others used computational methods. Heuristic algorithms are used by 23% of fuzzy-based scheduling algorithms, while meta-heuristic algorithms are used by 60%. Heuristics are used based on the problem at hand. It is possible to maximize their specific benefits since they are typically customized.

Classification of fuzzy-based task scheduling algorithms
In contrast, a meta-heuristic is an independent technique. In order to explore the solution space more thoroughly, they may temporarily depreciate the solution. Although meta-heuristics are problem-independent, they have to be fine-tuned to fit the particular problem. Around 16% of the algorithms discussed in this paper use metaheuristic algorithms. Figure 30 illustrates the percentages of different meta-heuristic algorithms. About 34% of algorithms use the well-known meta-heuristic algorithm PSO, and about 34% use GA.

The percentage of meta-heuristic algorithms
6.6 Analysis of QoS parameters
Figures 31, 32 and 33 illustrate the percentage of different QoS parameters considered by different scheduling algorithms in cloud, fog, and grid environments. Most articles consider not only the makespan time, but also the response time and execution time. Furthermore, most articles ignore important factors like security, resource allocation, and rotation time. Makespan time is considered in clouds around 46%, in fog around 25%, and in grid around 50%.

The percentage of QoS parameters considered by scheduling algorithms in the Cloud environment

The percentage of QoS parameters considered by scheduling algorithms in the Fog environment

The percentage of QoS parameters considered by scheduling algorithms in the Grid environment
The makespan time and cost in a cloud environment (see Fig. 31) are primarily considered, while rotation time and latency rate are not. Based on Fig. 32, fog environment algorithms are designed to minimize execution time, task migration, response time, and energy consumption. Figure 33 shows that grid environment articles placed more emphasis on makespan time than other factors, but not on resource allocation.
Nowadays, distributed systems need to be secured. Information must remain private regardless of whether it is stored or sent over a network. Many of the advantages of cloud/fog computing may be incompatible with traditional security models and controls. Distributed environments can present security challenges, especially for businesses that own their own infrastructure and computational resources and sell services to consumers. It is crucial to ensure information confidentiality, integrity, and authenticity when using real-time IoT applications (such as smart healthcare and smart homes). Security service in distributed environment is extremely complex compared with that in a traditional data center (Pourzandi et al. 2005). An attack surface with many compute resources in a cloud can be large. It is important to incorporate security modeling into task scheduling, performance, and trust QoS requirements to improve cloud service quality. Fuzzy logic is a straightforward method for modelling such parameters. In real-time system scheduling research, scheduling constraints are typically assumed. Generally, these parameters suggest using fuzzy logic to determine how to order the requests in such situations so that the system can be used more efficiently and to minimize the chances of requests getting missed or delayed. As a result, scheduling parameters will be considered fuzzy variables. Swamy and Mandapati (2018a, b) defined input variables for fuzzy systems as job length, VM memory, security level, and energy consumption. With this algorithm, customers will be able to receive their orders on time. Ali and Sridevi (2023) proposed a novel task scheduling algorithm that utilizes fuzzy logic to optimize the distribution of tasks between the fog and cloud layers. The algorithm selects the right processing unit based on the requirements of the task (e.g., computation, storage, bandwidth, security). Sujana et al. (2018) presented a fuzzy-based decision model. As a result, the most secure VM can be chosen for the workflow tasks. Integrity, confidentiality, and authentication are taken into account when ensuring security.
6.7 Comparison based on the fuzzy logic usage
Table 18 presents the use of fuzzy logic in the reviewed papers. There are many practical and commercial problems that can be solved using fuzzy logic systems. Furthermore, it can be applied to product and control machines for consumers, to managing engineering uncertainty, and to providing acceptable but not exact reasoning. Further, fuzzy logic is advantageous for a various of problems because of its unique features (see Table 19).
There has been considerable research interest in fuzzy logic to improve computing environments in many fields, including resource management, fog security, and attack detection and prediction. A brief overview of different uses of fuzzy logic in scheduling studies is provided here (see Fig. 34).
-
IoT data generated by fog cannot be processed locally due to the limited resources available. Thus, it will be essential to choose between the fog layer and the cloud layer. Further, the heterogeneity of fog resources and the varying requirements of tasks influence task execution efficiency. Several task scheduling algorithms use fuzzy logic to optimize task distribution between cloud and fog layers, taking into account different task characteristics, including the task length, deadline, security demand, and resource constraints.
-
It is necessary for the service provider to balance conflicting objectives such as decreasing overall operation costs and minimizing resource wastage. The fitness function in some scheduling algorithms is based on fuzzy systems for choosing the most appropriate node to serve the tasks of the users. This step mainly uses fuzzy theory to assign the best node to tasks based on task characteristics (e.g., task length and file size) and resource characteristics (e.g., CPU speed and storage).
-
In order to schedule the new workflow, the ready tasks must be obtained. During the scheduling process, the ready tasks change dynamically. Each ready task is scheduled sequentially. Performance of the proposed method depends on the way ready tasks are sorted. In order to prioritize, several criteria must be taken into account. To prioritize tasks, we can use criteria such as completion time, energy consumption, bandwidth, RAM, and deadlines. The AHP and fuzzy methods are used by some schedulers to prioritize tasks based on several important factors.
-
To reduce the range of resources available, resource clustering methods have been proposed. The optimization of fuzzy clustering has been proposed in some studies to facilitate resource scheduling. It is effective to classify resources using fuzzy clustering algorithms. Besides, fuzzy theory can solve problems involving uncertain resource attributes. Since the centers are randomly selected, iterative fuzzy c-means clusters are simple, but can easily lead to local ideals. To achieve global optimization, some works combined fuzzy clustering algorithms with metaheuristics (e.g., PSO). For example, fog computing has three types of resource attributes: computation, storage, and bandwidth. There are different types of tasks that require different resources. Some computational tasks require computational resources, whereas others require bandwidth resources. Therefore, we first cluster the resource to meet the needs of various users.
-
The fuzzy dominance method has been applied to compare multi-objective scheduling problems in several studies. Using membership functions, each solution will be assigned a fuzzy dominance value that will reflect the degree to which it dominates the other solutions in the set. A solution with a low fuzzy dominance value is better. The Pareto front can be easily found by sorting solutions according to their fuzzy dominance values. The best K solutions were found and selected using a fuzzy dominance sorting method in each round.
-
In a few studies, fuzzy logic was combined with resource utilization to determine reliability constraints.

An overview of fuzzy logic's use in scheduling
Table 20 summarizes the main characteristics of fuzzy logic that are used in studied papers.
6.7.1 Fuzzy functions
The most relevant information regarding fuzzy usage was collected from each reviewed article. Triangular and trapezoidal membership functions are the most famous. The fuzzy function can be divided into three groups based on how the fuzzy concept is applied to the crisp function (Lee 2005).
-
Crisp function with fuzzy constraint: Consider X and Y to be crisp sets, and f to be crisp functions. The fuzzy sets A and B are defined respectively on universal sets X and Y. Normally, the function that meets the condition \({\mu }_{A }(x) \le {\mu }_{B }\left(f\left(x\right)\right)\) is referred to as a fuzzy domain A function, and a fuzzy range B function, respectively.
-
Fuzziness propagation from independent to dependent variables: As a result of fuzzy extension functions, the ambiguity of independent variables is propagated to dependent variables. An image f (\(\widetilde{X}\)) of fuzzy set \(\widetilde{X}\) can be defined by f as a crisp function from X to Y. (The sign ~ stands for fuzzy variable.). Therefore, the extension principle is used:
$${\mu }_{f (\widetilde{X})}(y)=\left\{\begin{array}{ll}\max {\mu }_{\widetilde{X} }(x) & \quad if\; {f}^{-1}(y)\ne \varnothing \\ 0& \quad if\; {f}^{-1}(y)=\varnothing \end{array}\right.$$(1) -
Function that is itself fuzzy: In this fuzzifying function, independent variables are blurred.
Defining membership functions for inputs and outputs is also an important part of fuzzy logic. A membership function on X is a function from X to the real unit interval [0, 1]. A fuzzy set's membership function is usually denoted as \({\mu }_{A}.\) Selecting the appropriate types and parameters for membership functions is important for creating a fuzzy logic model (Rajabi et al. 2010; Rezaee et al. 2008; Shukla et al. 2023; Zhang and Zheng 2023). A mathematical formula is a more convenient and concise way to define an MF. Fuzzy logic system design is very delicate because membership functions must satisfy only one restriction: they must have values between [0,1]. The membership functions of fuzzy sets are infinite, unlike crisp sets (Ghoneim et al. 2023). In fuzzy logic, membership functions represent the degree of truth. Common membership functions include triangular, trapezoidal, sigmoidal, Gaussian, Singleton, and S-shaped (see Fig. 35).

Common fuzzy membership functions
Table 21 compares membership functions. As shown in Table 21, the choice of a membership function is largely determined by the degree of certainty (degree of truth) associated with an input space. It is possible to generalize crisp set operations to fuzzy sets using fuzzy set operations. Most papers used if–then, AND, and OR operators for implementing fuzzy rules, but some didn't specify the fuzzy operator they used. There are 21 articles out of 35 without mentioning the type of fuzzy inference; however, Mamdani is the most popular type. A defuzzing process generates quantifiable values from actionable outcomes. An inference system that uses fuzzy inference greatly depends on the defuzzification technique selected. Several common types of defuzzification exist, including Center of Gravity/Centroid (COG), Last of Maxima (LOM), Mean of Maxima (MOM), Center of Area (COA), Center of Largest Area (COLA), and Maxima Average methods. These popular defuzzification technique are defines as follow (Fuchs and Masoum 2023):
-
Maxima methods select crisp outputs from the core set. Core elements are those with the highest membership degree in the fuzzy output. The logic behind this method relies on the fact that it provides the best possible result. The fuzzy number does not take into account the remaining information, so it is not always accurate (Rondeau et al. 1997). There are several variants of the maxima method:
-
(1)
First of Maxima: It selects the smallest element among the core elements. As a result of defuzzing, the output is as follows:
$${x}^{*}=\mathit{min}({x}_{core}).$$(2) -
(2)
Last of Maxima: According to Eq. (3), the greatest element is selected from the core elements.
$${x}^{*}=\mathit{max}({x}_{core})$$(3) -
(3)
Mean of Maxima: The mean value is calculated as the defuzzified output.
$${x}^{*}=\frac{{\sum }_{j=1}^{m}{x}_{j}}{m}$$(4)
-
(1)
-
Defuzzified values are estimated based on the area under the curve of fuzzy output. These derivatives of defuzzification are given below.
-
(1)
Center of Area (COA): The defuzzied value is found by dividing the area under the curve of the final fuzzy output into equal portions.
$$\underset{{x}_{lb}}{\overset{{x}^{*}}{\int }}x{\mu }_{{c}{\prime}}\left(x\right)dx={\int }_{{x}^{*}}^{{x}_{ub}}x{\mu }_{{c}{\prime}}\left(x\right)dx$$(5) -
(2)
Center of Gravity/Centroid (COG): Defuzzification by center of gravity (C′) is a widely used technique that determines the final fuzzy output by Eq. (6). In addition to taking into account all the information provided by this number, this method offers a logical compromise between all possible solutions. Nonetheless, it is not always the most appropriate solution and, therefore, does not always choose the optimal solution.
$${x}^{*}=\frac{\underset{{x}_{lb}}{\overset{{x}_{ub}}{\int }}x{\mu }_{{c}{\prime}}\left(x\right)dx}{\underset{{x}_{lb}}{\overset{{x}_{ub}}{\int }}{\mu }_{{c}{\prime}}\left(x\right)dx}$$(6) -
(3)
(3) Center of Largest Area (COLA): A convex fuzzy subset with at least two convex fuzzy areas produces the crisp output by finding its center of gravity.
$${x}^{*}=\frac{\underset{{x}_{Llb}}{\overset{{x}_{Lub}}{\int }}x{\mu }_{{\widetilde{c}}_{m}}\left(x\right)dx}{\underset{{x}_{Llb}}{\overset{{x}_{Lub}}{\int }}{\mu }_{{\widetilde{c}}_{m}}\left(x\right)dx}$$(7)Assume that \({x}_{Llb}\) and \({x}_{Lub}\) are the lower and upper bounds of x that correspond to the largest convex fuzzy subset \({\widetilde{c}}_{m}\) of \(\widetilde{c}\), respectively. The membership function of \({\widetilde{c}}_{m}\) is \({\mu }_{{\widetilde{c}}_{m}}\).
-
(1)
Center of Gravity/Centroid (COG) and Center of Area (COA) are two common defuzzification methods. COG returns an accurate value based on the fuzzy set’s center of gravity. In order to describe combined control actions, the membership function distribution is divided into several sub-areas (e.g., triangles, trapezoids, etc.). The area and centroid of each subregion are calculated. The defuzzified value of a discrete fuzzy set is determined by the sum of all these sub-areas. The computations in COG are intensive (Rondeau et al. 1997).
6.7.2 Fuzzy usage in scheduler
Figure 36 shows an example of fuzzy reasoning used by the scheduler for Resource Domain (RD) selector. At every schedule, resources domain states are determined by variables dealing with the state of machines usage as well as results at the time of scheduling. First, we select Mamdani FIs. The expert system’s rule base (step 3) describes the input variables with two rules. In step 7, the membership functions for this input \({\mu }_{{A}_{i,m}}^{({x}_{m})}\) are depicted (along with the degrees of membership in step 4). As a next step, a truth value for every rule within the rule base is determined using the min or AND method (operator) and results are obtained in step 5. The inference system uses the implicatory operator to infer fuzzy sets by applying each individual linguistic rule. Step 7 illustrates how the inference engine operates graphically by displaying the membership functions. Defuzzification interfaces aggregate output fuzzy sets based on the maximum aggregation operator as indicated in step 8. The aggregated fuzzy set is defuzzied using the 'center of gravity' strategy. A final value of y0 = 0.638 indicates the degree of suitability for the RD.

A fuzzy system example in scheduler (García-Galán et al. 2012)
Fuzzy system output is used in several ways by scheduler, but the most common ones are:
-
Scheduler compares the output crisp value of fuzzy system with the predefined decision threshold. An example of such an algorithm would be task distribution using fuzzy-based decision algorithms in fog-cloud environment. To determine whether the task should be offloaded to the cloud, the crisp value C is obtained through defuzzification and compared with the predefined decision threshold T.
-
In fuzzy-based fitness computation, the final value after defuzzification indicates the level of suitability for selecting the considered node.
-
Task prioritization is determined by the final values obtained after defuzzification; a higher final value indicates that a task will be selected earlier in the scheduling process. For example, scheduler calculates a lambda (λ) value based on task characteristics (e.g., resource required, cost, and primary priority) using fuzzy system. The defuzzification process is used to determine the next task to schedule. It presents a sorted list of tasks according to λ value and schedules them one by one.
-
A fuzzy system determines the priority of available machines, which are then stored in a priority list. Schedulers use this list to map tasks to available machines based on priorities. Machines with higher priorities have better conditions for receiving tasks. The highest priority machines will therefore be assigned tasks first.
7 Possible future research directions
In this paper, several fuzzy-based scheduling techniques for grids, clouds, and fogs are explained and reviewed. Distributed computing performance can be enhanced by developing more dynamic and intelligent algorithms, as well as solving scheduling problems. We begin by summarizing interesting ways to enhance the fuzzy mechanism. Afterwards, we discuss the deployment of fuzzy-based scheduling to improve system performance. A summary of open issues related to fuzzy logics is shown in Fig. 37.

Research issues to improve fuzzy approaches
Although significant progress has been made in fog and cloud computing scheduling. Nevertheless, there are many challenges to overcome in this area. On the basis of existing literature, we have developed a list of outstanding challenges in this area.
7.1 Heterogeneity of fog and edge environments
Several models have been developed by cloud service providers and customers to reduce uncertainty and complexity. Various attributes are taken into account in different models. The comprehensive quality model must be evaluated with expert techniques to prevent mismatches between cloud service providers and users. Although cloud computing is popular and has been used in many parts, fog computing has appeared in recent years and has something to offer. In future work, fuzzy task scheduling can be more focused in fog and edge environments. The IoT applications will emerge in a wide variety of programming languages and hardware architectures. The problem of resource management is highly challenging due to such heterogeneity. Therefore, a resource manager, like a resource balancer, needs to understand these differences. Without homogeneous-based solutions, resource managers would waste considerable resources and make inappropriate decisions. As an example, developing innovating strategies based on the environmental and task history is interesting. Additionally, live migration of multiple VMs is another important issue that should be taken into account. A parallel scheduling process and the separation of tasks into subtasks can also reduce delays in distributed computing.
7.2 Real-life evaluations
Many papers lacked a realistic environment for evaluating their proposed algorithms or did not use a simulator. In future papers, it is better to evaluate algorithms in real environments. The use of metrics in simulation environments may be inapplicable to real-life evaluations, or transferring them may take a lot of time and effort. Additionally, there may be metrics that have been identified as a result of the intersection of IoT with new computing landscapes. Most cloud, fog, and edge optimization studies focus on simple measurements, such as response and delay times, which are often measured by average. For example, a driverless car application could activate the brakes when a hazard is recognized. It is necessary to investigate multiple time metrics, such as time to adaptation and resource lifetime.
7.3 Multi-objective scheduling
The design of task scheduling algorithms usually involves one or two parameters. The energy and execution time parameters of one algorithm are taken into account, but other QoS parameters such as response time, reliability, and cost of execution are not. Other algorithms consider only energy and response time, and do not consider other factors, like throughput, fault tolerance, or scalability. Algorithms can be improved by adding additional criteria and focusing on economy-based preemption techniques. It is possible to improve fault tolerance using dynamic clustering algorithm in combination with other scheduling techniques.
The multi-objective nature of cloud and fog scheduling has led to many multi-objective algorithms being proposed to solve this problem. Among these methods, Pareto-based methods attracted the most attention. In order to overcome the drawbacks of these methods, such as improving diversity and showing uncertainty better, it is possible to use other types of fuzzy sets, including (interval) type-2 fuzzy sets or intuitionistic fuzzy sets. In this regard, the domination concept and the crowding distance are viewed as fuzzy parameters to generate (find) the best Pareto set.
7.4 Task migration
The migration of tasks can help balance the access load and improve replica access and availability by balancing the access load. This issue has been addressed in five of 35 articles in different fields of distributed systems. Meeting real-time deadlines is an important aspect of QoS. Fuzzy logic-based approaches can improve the performance of deadline-constrained tasks. When migrating a VM that consumes steady resources, the minimum migration time, correlation, and migration control metrics need to be considered. PMs are virtualized so that hardware resources are shared between different components. Virtual machine performance is uncertain due to resource interference between VMs when resources are shared. The ability of fuzzy logic to represent uncertainty in a small search area makes it ideal for dynamic environments. Performance and QoS can be improved with fuzzy logic in SLAs.
7.5 Data replication
Another important issue is replication, which is closely related to migration. The use of pervasive data processing is becoming increasingly common, for example, in healthcare systems for delay-sensitive operations. In order to take advantage of these on-demand technologies, data replication management needs to be flexible. The mentioned subject has not yet been researched. Data replication can be achieved using the fuzzy system at different stages, such as assigning values to replicas.
7.6 Security
The importance of security in distributed systems is increasing. Figures 31, 32 and 33 show that the cloud's security parameter is only 13%, while the grid's is 8% and the fog’s is 12.5%. Researchers should pay more attention to the security factor. Decision makers must consider the risks associated with information systems before allocating budgets for security and treatment. Information systems contain a various of assets or components. Aggregating the risks of each component is a challenge. Information system components must be evaluated based on aggregated risk models. It is necessary to use the fuzzy set theory in the information security risk analysis area since there is uncertainty.
7.7 Forecasting of load
Due to the fact that resources are shared among multiple users, overloading of VMs is common in the distributed systems. By utilizing virtualization technology, multiple processing elements can access a single physical machine’s hardware resources. Resource sharing results in unpredictable performance of virtual machines because they compete for the same resources. A fuzzy logic approach has been applied at two levels. The first step involves allocating priorities to tasks, which can help in mapping tasks to virtual machines. As a second level, fuzzy logic is used to identify overloaded VMs that should be migrated before deadlines are missed.
Multi-variant and multi-constraint load unbalancing affects the performance and efficiency of computer resources. Fuzzy logic controllers need to handle uncertainty, robustness, and complexity as virtualized data centers and dynamic loads become more complex. Therefore, forecasting load balance using auto regression and type II fuzzy logic systems takes into account several factors (such as processing capacity and workload). Moreover, resource prediction techniques may help to select the most suitable computing equipment for each IoT application. Machine learning algorithms, such as linear regression, random forests, and neural networks, can be used to predict fog computing.
7.8 Dynamic task rescheduling
During the execution of services, conflict or plan changes may result in a delay in delivery and a series of nonlinear losses if the initial scheme is not rescheduled in time. Multiparticipant combinatorial optimization problems involving rescheduling cloud services are very difficult to solve. Coordination between service suppliers and construction of a reward mechanism to encourage their participation in rescheduling are difficult. Therefore, dynamic task rescheduling can be designed using game theory or fuzzy systems.
7.9 Failure prediction
Unpredicted and predicted failures can both be dealt with by fuzzy logic. Devices utilizing fog are susceptible to failure due to their mobility, response time, and power availability. In order to determine failure rates, each parameter's membership must be considered. The exact degree of membership of each parameter was determined through fuzzy logic. The Fog device would be considered unreliable if the number of unpredicted failures was high. The scheduling algorithm was made robust by using replication to handle failures for unreliable fog devices.
7.9.1 Hierarchical fuzzy inference systems
It is not possible to implement fuzzy systems using traditional methods that support cloud computing. As a result, factors like flexibility and portability are not considered. In this way, fuzzy logic models can be developed, implemented, deployed, and managed as a natural extension of fuzzy systems software in cloud computing. Fuzzy models must be designed, described (constructed), deployed, composed, and exploited in an effective proposal to be developed on cloud computing platforms. Semantic technology has been used to create fuzzy systems as cloud computing services. In recent years, fuzzy-based approaches have gained popularity in scheduling decision making. Most fuzzy-based approaches, however, focus on fuzzifications, defuzzification, and conventional inference engine design strategies. In a realistic environment, scheduling and offloading parameters may vary depending on the application, device, and environment. Fuzzy-based schedulers with many parameters exponentially increase the number of rule sets, resulting in Complex Fuzzy Inference Systems (CFIS). Due to the bottleneck in the decision-making process, CFIS-based schedulers perform poorly and cannot efficiently offload jobs. Developing a fuzzy-based scheduler for distributed environments requires a better inference strategy than conventional fuzzy inference engines. For instance, CART decision trees can be developed by clustering similar decision types according to Gini indexes.
Hierarchical fuzzy inference systems include several atomic fuzzy modules, with low-level modules feeding higher-level modules with outputs. The hierarchical system offers at least two advantages over a non-hierarchical one. This reduces “If–Then” rules, which simplifies the design of the system considerably. Another advantage is that partial solutions can be computed when tasks can be divided clearly or functional dependencies exist. As an example, inference modules are created based on the types of requirements at the leaf level. High level inference modules evaluate non-leaf metrics by comparing outputs from corresponding sub-inference modules.
8 Conclusion
The scheduling process is crucial for distributed systems since it distributes workloads and utilizes resources efficiently, which reduces the overall response time. The fuzzy optimization method is recommended for situations where parameters are unknown or aren't precisely defined in advance. In this field, researchers have gained significant insight through the use of fuzzy logic to model agent goals and constraints. Based on rules and fuzzy inference methods, this type of reasoning reduces uncertainty and enables an acceptable decision to be reached quickly. Many aspects of distributed computing systems use fuzzy theory. In this paper, the problem of scheduling is discussed through a comparative analysis of the algorithms that have been proposed by researchers over the past 18 years. This paper describes distributed systems and scheduling, briefly highlighting the related fuzzy logic concepts. Furthermore, the fuzzy systems used during scheduling are described, along with performance metrics and a detailed analysis of overall parameters. In addition, different ways of utilizing fuzzy logic in scheduling are described, as well as tools used to evaluate them. Each fuzzy-based scheduling method is discussed in terms of its advantages and limitations. It presents future challenges in the areas of mobility management, security and privacy, multi-objective scheduling optimization, and designing efficient fuzzy systems. Research in this field has gained an in-depth understanding through the current work.
References
Al-Tarawneh M, Al-Musa A (2022) Adaptive user-oriented fuzzy-based service broker for cloud services. J King Saud Univ Comput Inf Sci 34:354–364. https://doi.org/10.1016/j.jksuci.2019.11.004
Ali HS, Sridevi R (2023) Mobility and security aware real-time task scheduling in fog-cloud computing for IoT devices: a fuzzy-logic approach. Comput J. https://doi.org/10.1093/comjnl/bxad019
Ali HS, Rout RR, Parimi P, Das SK (2021) Real-time task scheduling in fog-cloud computing framework for IoT applications. In: 13th international conference on communication systems & networks (COMSNETS), pp 556–564. https://doi.org/10.1109/COMSNETS51098.2021.9352931
Alizadeh MR, Khajehvand V, Rahmani AM, Akbari E (2020) Task scheduling approaches in fog computing: a systematic review. Int J Commun Syst 33:4583. https://doi.org/10.1002/dac.4583
Arianyan E, Taheri H, Khoshdel V (2017) Novel fuzzy multi objective DVFS-aware consolidation heuristics for energy and SLA efficient resource management in cloud data centers. J Netw Comput Appl 78:43–61. https://doi.org/10.1016/j.jnca.2016.09.016
Asghari Alaie Y, Hosseini Shirvani M, Rahmani AM (2023) A hybrid bi-objective scheduling algorithm for execution of scientific workflows on cloud platforms with execution time and reliability approach. J Supercomput 79:1451–1503. https://doi.org/10.1007/s11227-022-04703-0
Bansal S, Aggarwal H, Aggarwal M (2022) A systematic review of task scheduling approaches in fog computing. Trans Emerg Telecommun Technol. https://doi.org/10.1002/ett.4523
Beigrezaei M, Toroghi Haghighat A, Rashidy Kanan H (2013) A new fuzzy based dynamic data replication algorithm in data grids. In: 13th Iranian conference on fuzzy systems (IFSC). https://doi.org/10.1109/IFSC.2013.6675676
Benblidia MA, Brik B, Merghem-Boulahia L, Esseghir M (2019) Ranking fog nodes for tasks scheduling in fog-cloud environments. In: 15th International wireless communications and mobile computing conference (IWCMC), pp 1451–1457. https://doi.org/10.1109/IWCMC.2019.8766437
Bharany S, Badotra S, Sharma S, Rani S, Alazab M, Jhaveri RH, Gadekallu TR (2022) Energy efficient fault tolerance techniques in green cloud computing: a systematic survey and taxonomy. Sustain Energy Technol Assess 53:102613. https://doi.org/10.1016/j.seta.2022.102613
Buyya R, Murshed M (2003) GridSim: a toolkit for the modeling and simulation of distributed resource management and scheduling for grid computing. Concurr Comput Pract Exp 14:1175–1220. https://doi.org/10.1002/cpe.710
Chen Z, Zhu Y, Di Y, Feng S (2015) A dynamic resource scheduling method based on fuzzy control theory in cloud environment. J Control Sci Eng. https://doi.org/10.1155/2015/383209
Chen D, Zhang X, Wang L, Han Z (2021) Prediction of cloud resources demand based on hierarchical Pythagorean fuzzy deep neural network. IEEE Trans Serv Comput 14:1890–1901. https://doi.org/10.1109/TSC.2019.2906901
Chiang ML, Hsieh HC, Cheng YH, Lin WL, Zeng BH (2023) Improvement of tasks scheduling algorithm based on load balancing candidate method under cloud computing environment. Expert Syst Appl 212:118714. https://doi.org/10.1016/j.eswa.2022.118714
Chopra N, Singh S (2014) Survey on scheduling in hybrid clouds. In: Fifth international conference on computing, communications and networking technologies (ICCCNT). https://doi.org/10.1109/ICCCNT.2014.6963050
Dong T, Xue F, Xiao CH, Zhang J (2021) Workflow scheduling based on deep reinforcement learning in the cloud environment. J Ambient Intell Humaniz Comput 12:10823–10835. https://doi.org/10.1007/s12652-020-02884-1
Fahmy MMM (2010) A fuzzy algorithm for scheduling non-periodic jobs on soft real-time single processor system. Ain Shams Engineering Journal 1:31–38. https://doi.org/10.1016/j.asej.2010.09.004
Farid M, Latip R, Hussin M, Abdul Hamid NAW (2020) Scheduling scientific workflow using multi-objective algorithm with fuzzy resource utilization in multi-cloud environment. IEEE Access 8:24309–24322. https://doi.org/10.1109/ACCESS.2020.2970475
Fuchs EF, Masoum MAS (2023) Optimal placement and sizing of shunt capacitor banks in the presence of harmonics. In: Power quality in power systems, electrical machines, and power-electronic drives, 3rd edn, pp 1017–1085. https://doi.org/10.1016/B978-012369536-9.50011-5
García-Galán S, Prado RP, Muñoz Expósito JE (2012) Fuzzy scheduling with swarm intelligence-based knowledge acquisition for grid computing. Eng Appl Artif Intell 25:359–375. https://doi.org/10.1016/j.engappai.2011.11.002
Ghafari R, Hassani Kabutarkhani F, Mansouri N (2022) Task scheduling algorithms for energy optimization in cloud environment: a comprehensive review. Clust Comput 25:1035–1093. https://doi.org/10.1007/s10586-021-03512-z
Gholami Shooli R, Javidi MM (2020) Using gravitational search algorithm enhanced by fuzzy for resource allocation in cloud computing environments. SN Appl Sci 2:195. https://doi.org/10.1007/s42452-020-2014-y
Ghoneim WAM, Elshenawy A, Lotfi RA (2023) A novel technique for implementing equidistant sinusoidal membership functions for fuzzy sets. In: IEEE IAS Global Conference on Emerging Technologies (GlobConET). https://doi.org/10.1109/GlobConET56651.2023.10150158
Gill SS, Arya RC, Wander GS, Buyya R (2018) Fog-based smart healthcare as a big data and cloud service for heart patients using IoT. In: International conference on intelligent data communication technologies and Internet of Things, pp 1376–1383. https://doi.org/10.1007/978-3-030-03146-6_161
Gou X (2021) Multi-objective task scheduling optimization in cloud computing based on fuzzy self-defense algorithm. Alex Eng J 60:5603–5609. https://doi.org/10.1016/j.aej.2021.04.051
Grandhi S, Wibowo S (2015) Performance evaluation of cloud computing providers using fuzzy multiattribute group decision making model. In: 12th International conference on fuzzy systems and knowledge discovery (FSKD). https://doi.org/10.1109/FSKD.2015.7381928
Guerrero C, Lera I, Juiz C (2022) Genetic-based optimization in fog computing: current trends and research opportunities. Swarm Evol Comput 72:101094. https://doi.org/10.1016/j.swevo.2022.101094
Guiffrida AL, Nagi R (1998) Fuzzy set theory applications in production management research: a literature survey. J Intell Manuf 9:39–56. https://doi.org/10.1023/A:1008847308326
Guo Y, Wan Z, Cheng X (2022) When blockchain meets smart grids: a comprehensive survey. High-Confidence Comput 2:100059. https://doi.org/10.1016/j.hcc.2022.100059
Gupta H, Dastjerdi AV, Ghosh SK, Buyya R (2017) iFogSim: a toolkit for modeling and simulation of resource management techniques in the internet of things, edge and fog computing environments. Softw Pract Exp 47:1275–1296. https://doi.org/10.1002/spe.2509
Haman A, Geogranas ND (2008) Comparison of Mamdani and Sugeno fuzzy inference systems for evaluating the quality of experience of hapto-audio-visual applications. In: IEEE international workshop on haptic audio visual environments and their applications.https://doi.org/10.1109/HAVE.2008.4685304
Hazra D, Roy A, Midya S, Majumder K (2018a) Energy aware task scheduling algorithms in cloud environment: a survey. Smart Innov Syst Technol 77:631–639. https://doi.org/10.1007/978-981-10-5544-7_62
Hazra D, Roy A, Midya S, Majumder K (2018b) Distributed task scheduling in cloud platform: a survey. Smart Innov Syst Technol 77:183–191. https://doi.org/10.1007/978-981-10-5544-7_19
Hicham GT, Chaker EA (2016) Cloud computing CPU allocation and scheduling algorithms using CloudSim simulator. Int J Electr Comput Eng (IJECE) 6:1866–1879. https://doi.org/10.11591/ijece.v6i4.10144
Houssein EH, Gad AG, Wazery YM, Suganthan PN (2021) Task scheduling in cloud computing based on meta-heuristics: review, taxonomy, open challenges, and future trends. Swarm Evol Comput 62:100841. https://doi.org/10.1016/j.swevo.2021.100841
Hosseini E, Nickray M, Ghanbari S (2022) Optimized task scheduling for cost-latency trade-off in mobile fog computing using fuzzy analytical hierarchy process. Comput Netw 206:108752. https://doi.org/10.1016/j.comnet.2021.108752
https://www.mathworks.com/help/fuzzy/types-of-fuzzy-inference-systems.html
Javanmardi S, Shojafar M, Persico V, Pescapè A (2020) FPFTS: a joint fuzzy particle swarm optimization mobility-aware approach to fog task scheduling algorithm for Internet of Things devices. Softw Pract Exp 51:2519–2539. https://doi.org/10.1002/spe.2867
Javanmardi S, Shojafar M, Mohammadi R, Nazari A, Persico V, Pescapè A (2021) FUPE: a security driven task scheduling approach for SDN-based IoT–Fog networks. J Inf Secur Appl 60:102853. https://doi.org/10.1016/j.jisa.2021.102853
Javanmardi S, Shojafar M, Mohammadi R, Persico V, Pescapè A (2023) S-FoS: a secure workflow scheduling approach for performance optimization in SDN-based IoT-Fog networks. J Inf Secur Appl 72:103404. https://doi.org/10.1016/j.jisa.2022.103404
Kaplan J (2005) Utility computing: a better model for outsourcing success. Technol Offshore Outsourcing Strateg. https://doi.org/10.1057/9780230518568_15
Kaur A, Kaur A (2012) Comparison of Mamdani-type and Sugeno-type fuzzy inference systems for air conditioning system. Int J Soft Comput Eng (IJSCE) 2:323–325
Khelifa A, Mokadem R, Hamrouni T, Charrada FB (2022) Data correlation and fuzzy inference system-based data replication in federated cloud systems. Simul Model Pract Theory 115:102428. https://doi.org/10.1016/j.simpat.2021.102428
Kulkarni RA, Patil SB, Balaji N (2017) Fuzzy based task prioritization and VM migration of deadline constrained tasks in cloud systems. In: International conference on inventive computing and informatics (ICICI). https://doi.org/10.1109/ICICI.2017.8365382
Kumar V, Laghari AA, Karim S, Shakir M, Brohi AA (2019) Comparison of fog computing & cloud computing. Int J Math Sci Comput 1:31–41. https://doi.org/10.5815/ijmsc.2019.01.03
Kumaresan G, Devi K, Shanthi S, Muthusenthil B, Samydurai A (2023) Hybrid fuzzy Archimedes-based light GBM-XGBoost model for distributed task scheduling in mobile edge computing. Trans Emerg Telecommun Technol. https://doi.org/10.1002/ett.4733
Kumari N, Yadav A, Jana PK (2022) Task offloading in fog computing: a survey of algorithms and optimization techniques. Comput Netw 214:109137. https://doi.org/10.1016/j.comnet.2022.109137
Lee KH (2005) First course on fuzzy theory and applications. In: Advances in Intelligent and soft computing. Springer, Berlin. https://doi.org/10.1007/3-540-32366-X
Li G, Liu Y, Wu J, Lin D, Zhao S (2019) Methods of resource scheduling based on optimized fuzzy clustering in fog computing. Sensors 19:2122. https://doi.org/10.3390/s19092122
Lindsay D, Gill SS, Smirnova D, Garraghan P (2020) The evolution of distributed computing systems: from fundamentals to new frontiers. Computing 103:1859–1878. https://doi.org/10.1007/s00607-020-00900-y
Liua H, Abrahamc A, Hassanien AE (2010) Scheduling jobs on computational grids using a fuzzy particle swarm optimization algorithm. Futur Gener Comput Syst 26:1336–1343. https://doi.org/10.1016/j.future.2009.05.022
López-Medina MA, Espinilla M, Cleland I, Nugent C, Medina J (2020) Fuzzy cloud-fog computing approach application for human activity recognition in smart Homes. J Intell Fuzzy Syst Appl Eng Technol 38:709–721. https://doi.org/10.3233/JIFS-179443
Machesa MGK, Tartibu LK, Okwu MO (2023) Performance analysis of Stirling engine using computational intelligence techniques (ANN & Fuzzy Mamdani Model) and hybrid algorithms (ANN-PSO & ANFIS). Neural Comput Appl 35:1225–1245. https://doi.org/10.1007/s00521-022-07385-0
Mala K, Priyadharshini S, Madhumathi R (2021) Resource allocation in cloud using enhanced max-min algorithm. In: 12th International conference on computing communication and networking technologies (ICCCNT). https://doi.org/10.1109/ICCCNT51525.2021.9579672
Mangalampalli S, Karri GR, Kose U (2023a) Multi objective trust aware task scheduling algorithm in cloud computing using whale optimization. J King Saud Univ Comput Inf Sci 35:791–809. https://doi.org/10.1016/j.jksuci.2023.01.016
Mangalampalli S, Karri GR, Satish GN (2023b) Efficient workflow scheduling algorithm in cloud computing using whale optimization. Procedia Comput Sci 218:1936–1945. https://doi.org/10.1016/j.procs.2023.01.170
Mansouri N, Mohammad Hasani Zadea B, Javidi MM (2019) Hybrid task scheduling strategy for cloud computing by modified particle swarm optimization and fuzzy theory. Comput Ind Eng 130:597–633. https://doi.org/10.1016/j.cie.2019.03.006
Mansouri N, Mohammad Hasani Zadea B, Javidi MM (2020) A multi-objective optimized replication using fuzzy based self-defense algorithm for cloud computing. J Netw Comput Appl 171:102811. https://doi.org/10.1016/j.jnca.2020.102811
Marwa M, Hajlaoui JE, Sonia Y, Omri MN, Rachid C (2023) Multi-agent system-based fuzzy constraints offer negotiation of workflow scheduling in fog-cloud environment. Computing 105:1361–1393. https://doi.org/10.1007/s00607-022-01148-4
Masdari M, Salehi F, Jalali M, Bidaki M (2017) A survey of PSO-based scheduling algorithms in cloud computing. J Netw Syst Manage 25:122–158. https://doi.org/10.1007/s10922-016-9385-9
Mehranzadeh A, Hashemi SM (2013) A novel-scheduling algorithm for cloud computing based on fuzzy logic. Int J Appl Inf Syst 5:28–31. https://doi.org/10.5120/ijais13-450939
Meriam E, Tabbane N (2017) A survey on cloud computing scheduling algorithms. Glob Summit Comput Technol. https://doi.org/10.1109/GSCIT.2016.6
Mohammad Hasani Zade B, Mansouri N, Javidi MM (2022) A two-stage scheduler based on new Caledonian Crow learning algorithm and reinforcement learning strategy for cloud environment. J Netw Comput Appl 202:103385. https://doi.org/10.1016/j.jnca.2022.103385
Mokni M, Yassa S, Hajlaoui JE, Omri MN, Chelouah R (2023) Multi-objective fuzzy approach to scheduling and offloading workflow tasks in fog-cloud computing. Simul Model Pract Theory 123:102687. https://doi.org/10.1016/j.simpat.2022.102687
Mondal HS, Hasan MT, Rahaman ME, Hasan R (2017) Enhancing secure cloud computing environment by detecting DDoS attack using fuzzy logic. In: 3rd International conference on electrical information and communication technology (EICT). https://doi.org/10.1109/EICT.2017.8275211
Mor B, Shabtay D, Yedidsion L (2020) Heuristic algorithms for solving a set of NP-hard single-machine scheduling problems with resource-dependent processing times. Comput Ind Eng 153:107024. https://doi.org/10.1016/j.cie.2020.107024
Moura BMP, Schneider GB, Yamin AC, Pilla ML, Reiser RHS (2018) Int-fGrid: BoT tasks scheduling exploring fuzzy type-2 in computational grids. In: IEEE international conference on fuzzy systems (FUZZ-IEEE). https://doi.org/10.1109/FUZZ-IEEE.2018.8491673
Murad SA, Muzahid AJMd, Azmi ZRM, Hoque MdI, Kowsher Md (2022) A review on job scheduling technique in cloud computing and priority rule based intelligent framework. J King Saud Univ Comput Inf Sci 34:2309–2331. https://doi.org/10.1016/j.jksuci.2022.03.027
Naha RK, Grag S, Georgakopoulos D, Jayaraman PP, Gao L, Xiang Y, Rajan R (2018) Fog computing: survey of trends, architectures, requirements, and research directions. IEEE Access 6:47980–48009. https://doi.org/10.1109/ACCESS.2018.2866491
Nanjappan M, Natesan G, Krishnadoss P (2021) An adaptive neuro-fuzzy inference system and black widow optimization approach for optimal resource utilization and task scheduling in a cloud environment. Wireless Pers Commun 121:1891–1916. https://doi.org/10.1007/s11277-021-08744-1
Pang S, Li W, He H, Shan Z, Wang X (2019) An EDA-GA hybrid algorithm for multi-objective task scheduling in cloud computing. IEEE Access 7:146379–146389. https://doi.org/10.1109/ACCESS.2019.2946216
Pezeshki Z, Mazinani SM (2019) Comparison of artificial neural networks, fuzzy logic and neuro fuzzy for predicting optimization of building thermal consumption: a survey. Artif Intell Rev 52:495–525. https://doi.org/10.1007/s10462-018-9630-6
Pourzandi M, Gordon D, Yurcik W, Koenig GA (2005) Clusters and security: distributed security for distributed systems. In: IEEE international symposium on cluster computing and the grid. https://doi.org/10.1109/CCGRID.2005.1558540
Pradeep K, Gobalakrishnan N, Manikandan N, Javid Ali L, Parkavi K, Vijayakumar KP (2021) A review on task scheduling using optimization algorithm in clouds. In: 5th International conference on trends in electronics and informatics (ICOEI). https://doi.org/10.1109/ICOEI51242.2021.9452837
Pradhan A, Bisoy SK, Das A (2022) A survey on PSO based meta-heuristic scheduling mechanism in cloud computing environment. J King Saud Univ Comput Inf Sci 34:4888–4901. https://doi.org/10.1016/j.jksuci.2021.01.003
Prado RP, García-Galán S, Yuste AJ, Muñoz Expósito JE (2010) Genetic fuzzy rule-based scheduling system for grid computing in virtual organizations. Soft Comput 15:1255–1271. https://doi.org/10.1007/s00500-010-0660-5
Pradoa RP, Hoffmannb F, García-Galána S, Muñoz Expósitoa JE, Bertram T (2012) On providing quality of service in grid computing through multi-objective swarm-based knowledge acquisition in fuzzy schedulers. Int J Approx Reason 53:228–247. https://doi.org/10.1016/j.ijar.2011.10.005
Qi P, Li L (2012) Job scheduling algorithm based on fuzzy quotient space theory in cloud environment. In: IEEE international conference on granular computing. https://doi.org/10.1109/GrC.2012.6468629
Radhika EG, Sudha Sadasivam G (2021) Budget optimized dynamic virtual machine provisioning in hybrid cloud using fuzzy analytic hierarchy process. Expert Syst Appl 183:115398. https://doi.org/10.1016/j.eswa.2021.115398
Ragmani A, Elomri A, Abghour N, Moussaid K, Rida M (2019) An improved hybrid fuzzy-ant colony algorithm applied to load balancing in cloud computing environment. Procedia Comput Sci 151:519–526. https://doi.org/10.1016/j.procs.2019.04.070
Rai K, Vemireddy S, Rout RR (2021) Fuzzy logic based task scheduling algorithm in vehicular fog computing framework. In: IEEE 18th India council international conference (INDICON). https://doi.org/10.1109/INDICON52576.2021.9691705
Rajabi M, Bohloli B, Gholampour Ahangar E (2010) Intelligent approaches for prediction of compressional, shear and Stoneley wave velocities from conventional well log data: a case study from the Sarvak carbonate reservoir in the Abadan Plain (Southwestern Iran). Comput Geosci 36:647–664. https://doi.org/10.1016/j.cageo.2009.09.008
Rajan CDS (2020) Design and implementation of fuzzy priority deadline job scheduling algorithm in heterogeneous grid computing. J Ambient Intell Humaniz Comput 12:6073–6080. https://doi.org/10.1007/s12652-020-02171-z
Raju MR, Mothku SK (2023) Delay and energy aware task scheduling mechanism for fog-enabled IoT applications: a reinforcement learning approach. Comput Netw 224:109603. https://doi.org/10.1016/j.comnet.2023.109603
Rani R, Garg R (2021) Reliability aware green workflow scheduling using ε-fuzzy dominance in cloud. Complex Intell Syst 8:1425–1443. https://doi.org/10.1007/s40747-021-00609-1
Rezaee MR, Kadkhodaie Ilkhchi A, Alizadeh PM (2008) Intelligent approaches for the synthesis of petrophysical logs. J Geophys Eng 5:12–26. https://doi.org/10.1088/1742-2132/5/1/002
Rondeau L, Ruelas R, Levrat L, Lamotte M (1997) A defuzzification method respecting the fuzzification. Fuzzy Sets Syst 86:311–320. https://doi.org/10.1016/S0165-0114(95)00399-1
Rong H, Zhigang H (2005) A scheduling algorithm aimed at time and cost for meta-tasks in grid computing using fuzzy applicability. In: 8th International conference on high-performance computing in Asia-Pacific Region (HPCASIA’05). https://doi.org/10.1109/HPCASIA.2005.11
Saleh AI (2012) An efficient grid-scheduling strategy based on a fuzzy matchmaking approach. Soft Comput 17:467–487. https://doi.org/10.1007/s00500-012-0920-7
Salimi R, Motameni H, Omranpour H (2012) Task scheduling with load balancing for computational grid using NSGA II with fuzzy mutation. In: 2nd IEEE international conference on parallel, distributed and grid computing, pp 79–84. https://doi.org/10.1109/PDGC.2012.6449795
Salimi R, Motameni H, Omranpour H (2014) Task scheduling using NSGA II with fuzzy adaptive operators for computational grids. J Parallel Distrib Comput 74:2333–2350. https://doi.org/10.1016/j.jpdc.2014.01.006
Samriya JK, Kumar N (2020) An optimal SLA based task scheduling aid of hybrid fuzzy TOPSIS-PSO algorithm in cloud environment. Mater Today Proc. https://doi.org/10.1016/j.matpr.2020.10.082
Saranya M, Ramesh R (2023) Dynamic data replication and scheduling using fuzzy CSO algorithm for IoT clouds. J Electr Eng Technol. https://doi.org/10.1007/s42835-023-01474-3
Septyanto AW, Rosyida I, Suryono S (2021) A fuzzy rule-based fog-cloud for control the traffic light duration based on-road density. Sixth International Conference on Informatics and Computing (ICIC). https://doi.org/10.1109/ICIC54025.2021.9632941
Shojafar M, Javanmardi S, Abolfazli S, Cordeschi N (2014) FUGE: a joint meta-heuristic approach to cloud job scheduling algorithm using fuzzy theory and a genetic method. Clust Comput 18:845. https://doi.org/10.1007/s10586-014-0420-x
Shukla AK, Nath R, Muhuri PK, Lohani QMD (2020) Energy efficient multi-objective scheduling of tasks with interval type-2 fuzzy timing constraints in an Industry 4.0 ecosystem. Eng Appl Artif Intell 87:103257. https://doi.org/10.1016/j.engappai.2019.103257
Shukla P, Pandey S, Hatwar P, Pant A (2023) FAT-ETO: Fuzzy-AHP-TOPSIS-based efficient task offloading algorithm for scientific workflows in heterogeneous fog-cloud environment. Proc Natl Acad Sci India Sect A 93:339–353. https://doi.org/10.1007/s40010-023-00809-z
Singh SP (2022) Effective load balancing strategy using fuzzy golden eagle optimization in fog computing environment. Sustain Comput Inf Syst 35:100766. https://doi.org/10.1016/j.suscom.2022.100766
Singla J (2015) Comparative study of Mamdani-type and Sugeno-type fuzzy inference systems for diagnosis of diabetes. In: International conference on advances in computer engineering and applications (ICACEA).https://doi.org/10.1109/ICACEA.2015.7164799
Soma P, Latha B, Vijaykumar V (2022) An improved multi-objective workflow scheduling using F-NSPSO with fuzzy rules. Wireless Pers Commun 124:3567–3589. https://doi.org/10.1007/s11277-022-09526-z
Sujana JAJ, Revathi T, Rajanayagam SJ (2018) Fuzzy-based security-driven optimistic scheduling of scientific workflows in cloud Computing. IETE J Res. https://doi.org/10.1080/03772063.2018.1486740
Swamy SR, Mandapati S (2018a) A fuzzy energy and security aware scheduling in cloud. Int J Eng Technol 7:117–124. https://doi.org/10.14419/ijet.v7i1.2.9021
Swamy SR, Mandapati S (2018b) A rule selected fuzzy energy & security aware scheduling in cloud. J Theor Appl Inf Technol 96:2826–2837
Talpur N, Abdulkadir SJ, Alhussian H, Hasan MH, Aziz N, Bamhdi A (2022) Deep neuro-fuzzy system application trends, challenges, and future perspectives: a systematic survey. Artif Intell Rev. https://doi.org/10.1007/s10462-022-10188-3
Tavousi F, Azizi S, Ghaderzadeh A (2021) A fuzzy approach for optimal placement of IoT applications in fog-cloud computing. Clust Comput 25:303–320. https://doi.org/10.1007/s10586-021-03406-0
Tsihrintzis GA, Virvou M (2021) Advances in core computer science-based technologies: a fuzzy task scheduling method, vol 14. Springer, Cham, pp 305–323. https://doi.org/10.1007/978-3-030-41196-1
Ul Islam MS, Kumar A, Hu YC (2021) Context-aware scheduling in fog computing: a survey, taxonomy, challenges and future directions. J Netw Comput Appl 180:103008. https://doi.org/10.1016/j.jnca.2021.103008
Vahdat-Nejad H, Monsefi R, Naghibzadeh M (2007) A new fuzzy algorithm for global job scheduling in multiclusters and grids. In: IEEE international conference on computational intelligence for measurement systems and applications, pp 54–58. https://doi.org/10.1109/CIMSA.2007.4362538
Vemireddy S, Rout RR (2021) Fuzzy reinforcement learning for energy efficient task offloading in vehicular fog computing. Comput Netw 199:108463. https://doi.org/10.1016/j.comnet.2021.108463
Verhoosel JPC, Luit EJ, Hammer DK, Jansen E (1991) A static scheduling algorithm for distributed hard real-time systems. Real Time Syst 3:227–246. https://doi.org/10.1007/BF00364957
Wadhonkar A, Theng D (2016) A Survey on different scheduling algorithms in cloud computing. In: International conference on advances in electrical, electronics, information, communication and bio-informatics (AEEICB16). https://doi.org/10.1109/AEEICB.2016.7538374
Wang K, Shang W, Liu M, Lin W, Fu H (2018) A greedy and genetic fusion algorithm for solving course timetabling problem. In: 17th International conference on computer and information science (ICIS). https://doi.org/10.1109/ICIS.2018.8466405
Wang J, Li X, Ruiz R, Yang J, Chu D (2022) Energy utilization task scheduling for Mapreduce in heterogeneous clusters. IEEE Trans Serv Comput 15:931–944. https://doi.org/10.1109/TSC.2020.2966697
Wu C, Li W, Wang L, Zomaya AY (2021) An evolutionary fuzzy scheduler for multi-objective resource allocation in fog computing. Futur Gener Comput Syst 117:498–509. https://doi.org/10.1016/j.future.2020.12.019
Xiaojun W, Yun W, Zhe H, Juan D (2015) The research on resource scheduling based on fuzzy clustering in cloud computing. In: 8th International conference on intelligent computation technology and automation, pp 1025–1028. https://doi.org/10.1109/ICICTA.2015.258
Ye L, Xia Y, Yang L, Wu C, Zhan Y (2022) A fuzzy scheduling strategy for online multi-workflows in IaaS clouds. In: 41st Chinese control conference. https://doi.org/10.23919/CCC55666.2022.9902489
Yu D, Ma Z, Wang R (2022) Efficient smart grid load balancing via fog and cloud computing. Hindawi Math Probl Eng. https://doi.org/10.1155/2022/3151249
Yuan M, Li Y, Zhang L, Pei F (2021) Research on intelligent workshop resource scheduling method based on improved NSGA-II algorithm. Robot Comput Integr Manuf 71:102–141. https://doi.org/10.1016/j.rcim.2021.102141
Zahoor S, Javaid S, Javaid N, Ashraf M, Ishmanov F, Afzal MK (2018) Cloud–fog–based smart grid model for efficient resource management. Sustainability 10:2079. https://doi.org/10.1109/IWCMC.2018.8450506
Zhang H, Zheng X (2023) Knowledge-driven adaptive evolutionary multi-objective scheduling algorithm for cloud workflows. Appl Soft Comput 146:110655. https://doi.org/10.1016/j.asoc.2023.110655
Zhang S, Chen X, Zhang S, Hou X (2010) The comparison between cloud computing and grid computing. In: International conference on computer application and system modeling (ICCASM).https://doi.org/10.1109/ICCASM.2010.5623257
Zhou Z, Deng W, Lu L (2009) A fuzzy reputation based ant algorithm for grid scheduling. In: International joint conference on computational sciences and optimization, vol 1, pp 102–104.https://doi.org/10.1109/CSO.2009.33
Zhou X, Zhang G, Sun J, Zhou J, Wei T, Hu S (2018) Minimizing cost and makespan for workflow scheduling in cloud using fuzzy dominance sort-based HEFT. Futur Gener Comput Syst 93:278–289. https://doi.org/10.1016/j.future.2018.10.046
Zhu J, Li X, Ruiz R, Li W, Huang H, Zomaya AY (2020) Scheduling periodical multi-stage jobs with fuzziness to elastic cloud resources. IEEE Trans Parallel Distrib Syst 31:2819–2833. https://doi.org/10.1109/TPDS.2020.3004134
Author information
Authors and Affiliations
Contributions
ZJKA: Data collection, literature search, draft manuscript preparation, comparing related works, preparing tables and figures. NM: Study design, investigation, analysis and interpretation of results, reviewing and editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Jalali Khalil Abadi, Z., Mansouri, N. A comprehensive survey on scheduling algorithms using fuzzy systems in distributed environments. Artif Intell Rev 57, 4 (2024). https://doi.org/10.1007/s10462-023-10632-y
Published:
DOI: https://doi.org/10.1007/s10462-023-10632-y